
 2019-09-03
2019-09-03
Just-in-time compilation w PostgreSQL 11 (benchmark EuroDB)
Wraz z wydaniem 11. silnika PostgreSQL, otrzymaliśmy nowe ciekawe narzędzie pozwalające na optymalizowanie szybkości wykonywania zapytań. Oczywiście mowa tu o kompilacji zapytań w locie (ang. just-in-time compilation). W tym artykule postaram się przybliżyć, dlaczego warto skorzystać z tego rozwiązania i jak wpływa ono na czas wykonywania analitycznych zapytań w EuroDB.
Wraz z wydaniem 11. silnika PostgreSQL, otrzymaliśmy nowe ciekawe narzędzie pozwalające na optymalizowanie szybkości wykonywania zapytań. Oczywiście mowa tu o kompilacji zapytań w locie (ang. just-in-time compilation). W tym artykule postaram się przybliżyć, dlaczego warto skorzystać z tego rozwiązania i jak wpływa ono na czas wykonywania analitycznych zapytań w EuroDB.
Czym jest JIT w PostgreSQL?
Rozpatrując ogólnie JIT – jest to technika służąca przyspieszaniu wykonywania zapytań, często spotykana w przypadku interpreterów języków skryptowych. Jako przykład możemy przywołać tu język JavaScript oraz jego interpreter V8, który korzysta z tego rodzaju optymalizacji. Patrząc z lotu ptaka, działa to w następujący sposób. Podczas wykonania dochodzi do częściowej kompilacji niektórych sekcji kodu w języku wysokiego poziomu do niskopoziomowych natywnych dla platformy instrukcji w czasie wykonywania programu.
By skorzystać z tego mechanizmu, PostgreSQL musi podczas kompilacji użyć bibliotek LLVM. W tym momencie do kompilowania w locie możliwe są jedynie operacje ewaluacji wyrażeń oraz odczytu z dysku krotek do ich reprezentacji w pamięci. Ponadto dodatkowymi mechanizmami pozwalającymi na optymalizację są tzw. inlining małych funkcji, który pozwala na zmniejszenie narzutu związanego z ich wywoływaniem oraz skorzystanie z dodatkowych zaawansowanych algorytmów optymalizacji kodu. Warto jednak nadmienić, że ich wykorzystanie nakłada dodatkowy narzut związany z czasem kompilacji zapytania.
W EuroDB 11 zdecydowaliśmy umożliwić korzystanie z JIT, jednak domyślnie jest on wyłączony. Natomiast w wersji 12 PostgreSQL, JIT będzie już domyślnie włączony. Warto więc zaznajomić się z tym mechanizmem już teraz. W tym celu, po połączeniu z bazą, wystarczy wywołać:
SET jit = 'on'
Spowoduje to uruchomienie mechanizmu JIT dla danego połączenia do serwera. Kolejnym istotnym „pokrętłem” w pliku konfiguracyjnym, pozwalającym na sterowanie kompilacją w locie, jest jit_above_cost. Domyślnie ustawioną wartością jest 100000. Jest to wartość graniczna, przy której zapytanie zostanie poddane tej optymalizacji. Dla pełności warto również wspomnieć o:
jit_inline_above_cost– steruje zachowaniem planera związanym z inlinowaniem funkcji. Domyślna wartość to500000,jit_optimize_above_cost– pozwala zdecydować, kiedy planer ma skorzystać z możliwości optymalizacji wynikowego natywnego kodu (co zwiększa narzut kompilacji, ale potencjalnie dodatkowo przyspiesza czas wykonania). Domyślna wartość to500000.
Przy pomocy tych parametrów będziemy mogli dynamicznie sterować wykorzystanymi optymalizacjami w czasie działania testów.
By sprawdzić, czy opcje faktycznie działają, można posłużyć się następującymi poleceniami:
postgres=# SHOW jit; jit ----- off (1 row) postgres=# SET jit = on; -- włączenie optymalizacji JIT SET postgres=# SHOW jit; jit ----- on (1 row) postgres=# SHOW jit_above_cost; jit_above_cost ---------------- 100000 (1 row) postgres=# SHOW jit_inline_above_cost; jit_inline_above_cost ----------------------- 500000 (1 row) postgres=# SHOW jit_optimize_above_cost; jit_optimize_above_cost ------------------------- 500000 (1 row)
Porównanie wydajności
Wykorzystanie JIT ma największe znaczenie dla zapytań, które intensywnie wykorzystują w swoim działaniu procesor. Najczęściej będą to długie zapytania analityczne – na przykład liczące statystyki z zebranych danych. W przypadku krótkich zapytań, wykorzystanie kompilacji może mieć wręcz skutek odwrotny od zamierzonego, doprowadzając do wzrostu czasu potrzebnego na skończenie zapytania.
Mając to na uwadze, do testów wykorzystałem prostą bazę o strukturze widocznej poniżej, z której następnie wygenerowałem prosty raport zbierający podstawowe statystyki.
System na potrzeby testów
Jako środowisko testowe posłużyła mi stworzona na szybko przy pomocy Vagranta maszyna wirtualna. Przy okazji serdecznie zapraszam do testowania naszych obrazów deweloperskich, o których pisaliśmy tutaj. Do testów wydajności posłużę się jednym z nich.
$ vagrant init eurolinux-vagrant/eurolinux-7
By umożliwić reprodukcję wyników, poniżej dodatkowo znajduje się Vagrantfile z modyfikacjami, które się tam pojawiły podczas testów.
Vagrant.configure("2") do |config|
config.vm.box = "eurolinux-vagrant/eurolinux-7"
config.vm.provider "libvirt" do |vb|
# Customize the amount of memory on the VM:
vb.cpus = 4
vb.memory = 4096
end
end
Kolejnym krokiem jest instalacja serwera PostgreSQL. Na potrzeby testów skorzystałem z EuroDB w wersji 11.4 oraz systemu EuroLinux. By odtworzyć przedstawione testy, można skorzystać z wersji community tego oprogramowania. Poniżej kroki instalacyjne dla systemu z aktywnymi repozytoriami:
# doinstalowane repozytorium PGDG oraz EPEL sudo yum install -y \ https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm \ https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # instalacja serwera sudo yum groupinstall -y "PostgreSQL Database Server 11 PGDG"
Z tak skonfigurowanym środowiskiem pozostaje utworzyć klaster oraz stworzyć testową bazę danych.
Testowa baza danych
Tabele, którymi posłużymy się do testów, mają następującą strukturę:
CREATE TABLE album (
id INT GENERATED ALWAYS AS IDENTITY,
artist TEXT NOT NULL,
title TEXT NOT NULL,
no_tracks INT NOT NULL,
unit_price NUMERIC NOT NULL,
release DATE NOT NULL
);
CREATE TABLE orders (
id INT GENERATED ALWAYS AS IDENTITY,
album_id INT NOT NULL,
quantity INT NOT NULL,
final_price NUMERIC NOT NULL
);
Jak widać, jest to wycinek bazy sklepu muzycznego. Na potrzeby testów wygenerowałem zestaw danych testowych przy pomocy narzędzia dostępnego w EuroDB, o którym pisaliśmy tutaj. Do przeprowadzenia testów skorzystałem ze standardowego narzędzia pgbench, wykorzystującego poniższe zapytania:
SELECT
orders.id AS basket_id,
count(orders.id) AS no_articles,
sum(quantity) AS no_items,
sum(final_price) AS total_basket_price,
sum(final_price) + sum(final_price) * 0.23 AS total_basket_price_tax,
sum(unit_price) AS total_unit_price,
avg(final_price) AS avg_price_in_basket,
max(final_price) AS max_price_in_basket,
min(final_price) AS min_price_in_basket,
avg(unit_price) AS avg_stock_price,
avg(no_tracks) AS avg_no_tracks_in_basket,
(sum(unit_price) - sum(final_price))/sum(unit_price) AS basket_discount_percent
FROM (orders JOIN album ON album.id = album_id)
GROUP BY orders.id
ORDER BY orders.id;
Zapytanie to powinno się dobrze optymalizować przy dużej liczbie zamówień dzięki wykorzystaniu JIT. Baza do testów jest niewielka (~4 GB), tak aby całość mogła się zmieścić w pamięci RAM używanego do testów systemu.
Testy polegały na włączeniu zapytań w pętli w czasie 10 minut. Poniżej uśrednione wyniki czasu potrzebnego na wykonanie tych zapytań.
Wyniki testu
Podczas przeprowadzonych testów udało mi się osiągnąć przyspieszenie na poziomie ~10% całkowitego czasu wykonania.
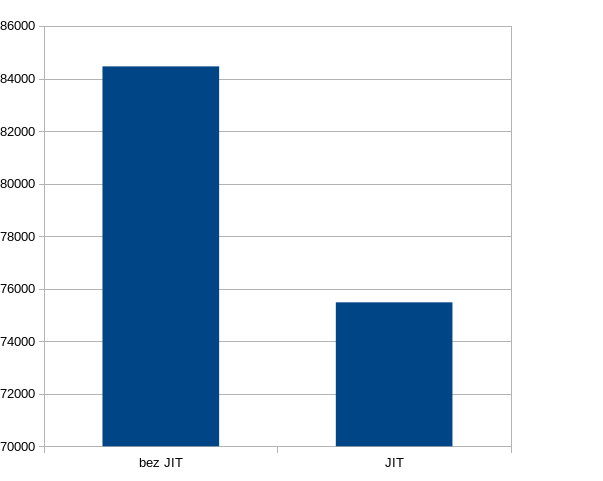
Średni czas zapytania z wyłączoną optymalizacją JIT wynosił 84461.028 ms, natomiast po włączeniu uzyskałem średni czas 75478.172 ms.
Podsumowanie
Wierzę, że nasi czytelnicy wykorzystają to porównanie wraz z krótką analizą w codziennej pracy. W szczególności mam nadzieję, że zaważy ono na decyzji o przenosinach do najnowszej wersji silnika umożliwiającej skorzystanie z mechanizmu kompilacji w locie – biorąc pod uwagę, że w wersji 12 będzie ona już domyślnie włączona. Zachęcam również do zapisania się na nasz newsletter, aby nie ominąć podobnych analiz. Dziękuję za czas spędzony na czytanie tego artykułu.