
 2022-08-22
2022-08-22
High Availability w PostgreSQL na przykładzie EuroDB
Standardowy system High Availability powinien być dostępny przez 99.999% czasu – może mieć 5 minut i 15,6 sekundy przerwy w działaniu w ciągu roku. Ze względu na ilość dziewiątek nazywamy go „five nines”. Istnieją jednak systemy „six nines” lub „seven nines”. W tym artykule przyjrzymy się bliżej zagadnieniu HA oraz omówimy rodzaje architektur systemów wysokiej dostępności w PostgreSQL.
Co kryje się pod frazą High Availability? Dlaczego tak wiele serwisów uważa je za podstawę projektu i jakie ma ono znaczenie dla współczesnego biznesu? W poniższym artykule przyjrzymy się bliżej temu tematowi i przedstawimy benefity związane z jego wykorzystaniem.
Rozpocznijmy od podstaw i samej definicji High Availability – w skrócie HA. Jest to system charakteryzujący się wysoką dostępnością, wydajnością oraz niezawodnością. Używa się go najczęściej do krytycznych zadań w wojskowości, w systemach zarządzania komunikacją lotniczą lub w mieście, a także do monitorowania stanu zdrowia w szpitalach,. Obecne możliwości technologiczne przesuwają granicę systemów krytycznych i to dzięki temu rozwojowi jesteśmy w stanie w dowolnej chwili zamówić jedzenie, odebrać paczkę, uruchomić robota sprzątającego czy też znaleźć odpowiedź na nurtujące nas pytania. Wszystko to jest dostępne dzięki przestrzeganiu trzech głównych reguł dotyczących projektowania systemów wysokiej dostępności:
- wyeliminowanie pojedynczych punktów awarii – czyli elementów infrastruktury, takich jak serwer lub usługa, których awaria powoduje problemy dla całego systemu
- utworzenie systemu przekierowującego – który w razie awarii jednego z elementów systemu zawiadamia inny o przejęciu jego zadań. Dzięki temu możliwa jest kontynuacja pracy systemu
- wykrywanie awarii przy ich wystąpieniu.
Powyższe zasady sprawiają, że przeciętny użytkownik może nie zauważyć awarii.
Czasy dostępności w systemach HA
System wysokiej dostępności powinien być dostępny przez 99.999% czasu. Inaczej mówiąc, może mieć 5 minut i 15,6 sekundy przerwy w działaniu w ciągu roku. Czas ten wydaje się znikomy, ale w niektórych przypadkach, gdzie stawką działania systemu jest ludzkie życie, nadal może okazać się zbyt wysoki. Aby zwiększyć rozróżnianie systemów HA ze względu na ich czas dostępności, stworzono zasadę nazewnictwa wykorzystującą dziewiątki.
Przykładowo, standardowy system HA, o którym mówiliśmy wcześniej, można zdefiniować jako „five nines”. Możemy sobie jednak wyobrazić, że istnieją systemy „six nines” lub nawet „seven nines”, lepsze odpowiednio o 10 lub 100 razy. Czasy rocznej niedostępności wynoszą dla nich odpowiednio 31,56 lub 3,16 sekundy.
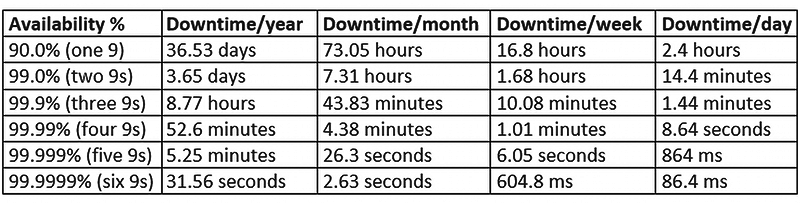
Żartobliwie dodaje się również termin „nine fives” (55,5555555%) jako kontrast do „five nines” (99,999%) w celu prześmiewczego określenia działania systemu, który notorycznie się psuje i stwarza problemy.
Zalety używania systemów High Availability
Posiadanie systemów wysokiej dostępności niesie ze sobą szereg zalet, z których najważniejszymi są:
- eliminacja przestojów w działaniu systemu
- wzrost bezpieczeństwa danych
- oszczędność pieniędzy, czasu i nerwów podczas naprawy całego systemu.
Wysoka dostępność systemów jest obecna coraz częściej nawet w małych i średnich przedsiębiorstwach, stając się powoli standardem. Dzięki temu firmy dają świadectwo stabilności i wiarygodności.
Rodzaje architektur systemów wysokiej dostępności w PostgreSQL
High Availability pełni również kluczową rolę dla wszelkich rodzajów baz danych, w szczególności w sektorach bankowości, zakupów online czy systemów identyfikacji (na przykład na lotniskach). Takie bazy posiadają wiele architektur służących do zarządzania systemami wysokiej dostępności. W Postgresie można rozgraniczyć je na dwa główne typy: Primary-Standby oraz Primary-Primary.
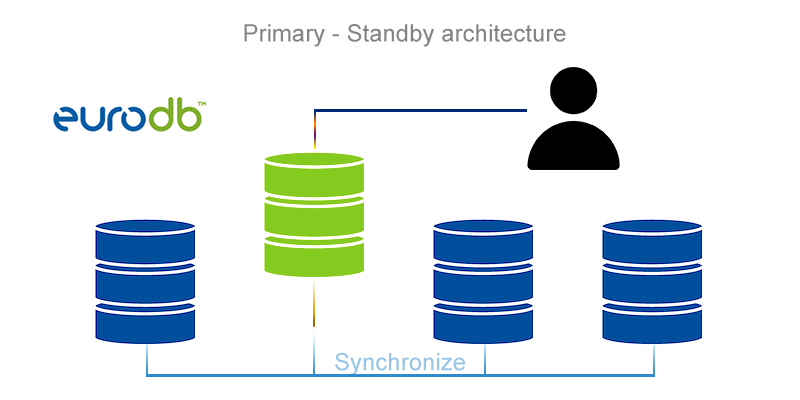
Primary-Standby
Architektura Primary-Standby jest najbardziej podstawową, a jednocześnie najłatwiejszą do zaimplementowania i utrzymania formą systemu High Availability. Cechuje się jedną główną bazą danych nazwaną „Primary” i wieloma bazami zapasowymi „Standby”, które są stale synchronizowane z główną bazą. Serwery zapasowe, posiadając wszelkie możliwe informacje z głównej bazy danych, mogą w razie awarii bardzo szybko zamienić się w bazę „Primary”. Wyróżniamy dwa główne typy zapasowych baz danych „Standby”:
- logiczną – replikacja między bazami „Primary” a „Standby” odbywa się jedynie poprzez kopiowanie wykonywania zapytań SQL
- fizyczną – replikacja między bazami „Primary” a „Standby” jest wykonywana dzięki przesyłaniu informacji o modyfikacjach struktury bazy danych.
Aby zachować maksymalną pewność zsynchronizowania bazy „Standby” PostgreSQL używa specjalnych logów WAL (write-ahead log), które przechowują wszelkie informacje o zmianach w bazie danych.
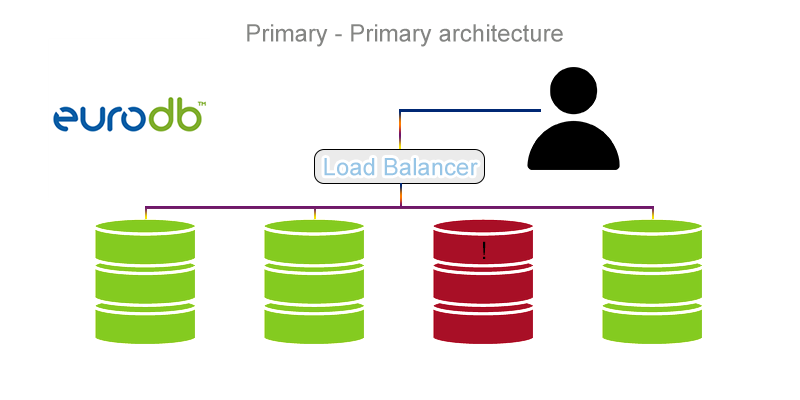
Primary-Primary
W przeciwieństwie do poprzedniczki architektura Primary-Primary nie posiada serwerów zapasowych, ale za to wiele baz „Primary” mogących zapisywać oraz odczytywać dane. Delikatnie tracąc na prędkości odpowiedzi, zyskujemy niezawodność w działaniu, co jest świetnym rozrachunkiem.
Architektura ta jest niestety bardziej skomplikowana do stworzenia i wymaga poznania terminu Load Balancingu, czyli równoważenia obciążenia. Jest to technologia służąca do przyporządkowania obciążenia różnym elementom systemu, na przykład bazom danych. Aplikacje, które do tego służą, nie tylko zarządzają obciążeniem każdej z baz, ale również przydzielają do niej kolejne zapytania, jeżeli wykryją jej prawidłowe działanie.
Failover w PostgreSQL
Należy pamiętać, że dzięki samemu stworzeniu odpowiedniej architektury nie nadamy systemowi statusu High Availability, ponieważ spełnia on tylko jedną regułę systemów HA, czyli „wyeliminowanie pojedynczych punktów awarii”. Kolejnym krokiem do stworzenia systemu wysokiej dostępności jest wprowadzenie mechanizmu failover, który zakłada, że podczas awarii serwera lub jakiegokolwiek elementu systemu, inny przejmuje jego rolę.
Na przykładzie architektury Primary-Standby, byłaby to sytuacja, w której baza danych „Primary” ulega awarii, więc jedna z wcześniej określonych baz „Standby” zostaje przekształcona do „Primary”, jednocześnie przejmując jej zadania. Należy zaznaczyć, że podczas awarii jednego z serwerów „Standby” failover nie jest uruchamiany. Dzieje się to dlatego, że bez żadnej dodatkowej ingerencji system jest nadal aktywny i działający.
Mechanizm failover jest natywnie dostępny w platformie EuroDB i doskonale sprawdza się z innymi dostarczanymi w ramach tego rozwiązania narzędziami administracyjnymi, które na bieżąco informują o stanie systemu, jak też również przeszukują logi w poszukiwaniu potencjalnych błędów. System, który jest skonfigurowany w taki sposób, że zapewnia mechanizm failover i dodatkowo informuje o swoim statusie administratorów, zasługuje na miano systemu z wysoką niezawodnością.
Podsumowanie
Sprawdzonym sposobem na zapewnienie firmie dodatkowego poczucia bezpieczeństwa i zaufania wśród klientów, jest przekształcenie systemu na zgodny z regułami systemu o wysokiej dostępności. Benefity z wprowadzenia HA mogą nie być na pierwszy rzut oka widoczne. Jednak w perspektywie czasu zawsze zdarzą się jakieś awarie. Dlatego jedyne, co możemy zrobić, to z góry przygotować się na nie. Gdy przychodzi czas naprawy awarii, specjaliści również czują się o wiele bardziej komfortowo w sytuacji, gdy system cały czas jest aktywny i działający. Dochodzi do tego również świadomość, że błąd występuje tylko na jednej z kilku dostępnych kopii bazy danych.
Używając EuroDB, którego centralnym komponentem jest silnik PostgreSQL, mamy możliwość skorzystania z wielu narzędzi ułatwiających monitorowanie, administrowanie, jak również tworzenie od początku systemu wysokiej dostępności. Przygotowane narzędzia są gotowe do stworzenia architektury typu Primary-Standby, wraz z dostępem do mechanizmu failover. Dodatkową zaletą posiadania platformy EuroDB jest też profesjonalna asysta techniczna realizowana przez certyfikowanych architektów i inżynierów.