
 2020-05-19
2020-05-19
Mechanizmy replikacji w PostgreSQL
W jaki sposób działa replikacja w PostgreSQL? Który z dostępnych mechanizmów wybrać? To tylko kilka z często zadawanych pytań podczas planowania produkcyjnych wdrożeń Postgresa. W tym artykule przybliżymy możliwości replikacji w najbardziej zaawansowanej otwartoźródłowej bazie danych.
W jaki sposób działa replikacja w PostgreSQL? Który z dostępnych mechanizmów wybrać? To tylko kilka z często zadawanych pytań podczas planowania produkcyjnych wdrożeń Postgresa. W tym artykule przybliżymy możliwości replikacji w najbardziej zaawansowanej otwartoźródłowej bazie danych.
Artykuł ten jest wstępem do szerszego opisu zagadnienia, jakim jest wysoka dostępność (ang. High availability) do danych z wykorzystaniem PostgreSQL. Wysoka dostępność najczęściej wymaga połączenia 3 składników – kilku współpracujących serwerów bazodanowych, mechanizmu monitorowania stanu serwera głównego oraz rozwiązania, które pozwoli na stworzenie pewnej abstrakcji na klastrze bazodanowym z punktu widzenia aplikacji. Dziś skupimy się na mechanizmach umożliwiających współpracę, czyli przejęcie obsługi zapytań w przypadku awarii serwera głównego. Aby to osiągnąć, obydwa serwery muszą mieć dostęp do tych samych danych. Rozwiązaniem, które to umożliwia, jest replikacja, o której pisaliśmy już wcześniej na naszym blogu.
Podstawowa nomenklatura związana z replikacją
Przez ten tekst będzie się przewijało kilka pojęć, dlatego warto zacząć od ich zdefiniowania:
- serwer master/primary – serwer, który akceptuje operacje zapisu oraz odczytu. Działa jako serwer główny, z którego zmiany są propagowane do serwerów pomocniczych
- serwer standby/secondary – serwer, do którego replikowane są zmiany. Jest serwerem zapasowym, przejmującym rolę serwera głównego w przypadku jego awarii. Może obsługiwać operacje odczytu.
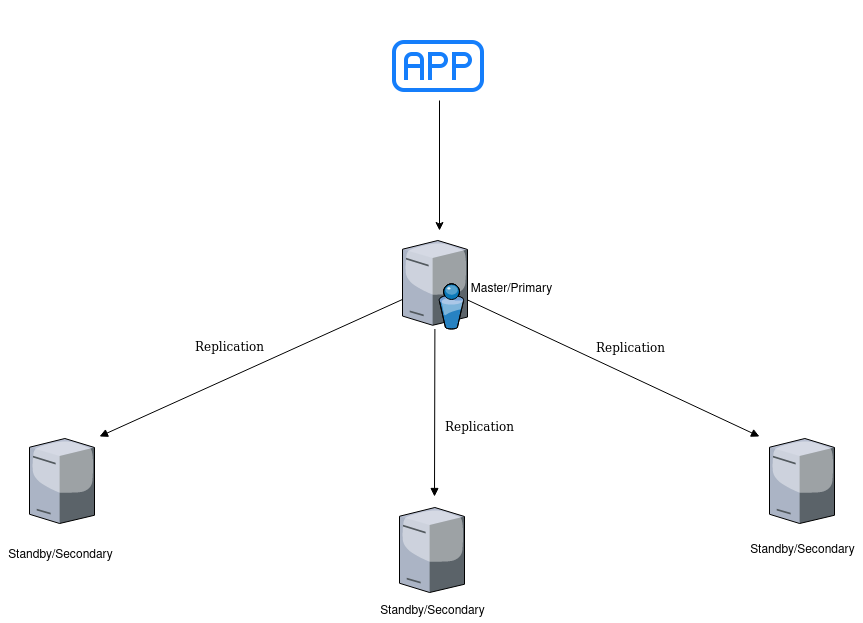
Formy replikacji w PostgreSQL
W tym momencie warto jeszcze wspomnieć o kategoriach, według których można podzielić replikację. Po pierwsze, istotne może być, aby dane na serwerze standby zawsze były aktualne względem stanu na serwerze master. Taki stan rzeczy zapewnia replikacja synchroniczna. Wiąże się to jednak z narzutem wydajnościowym, ponieważ wprowadzenie zmian musi zostać potwierdzone przez serwery zapasowe. Im mniejsza latencja na połączeniach między nimi, tym szybsze będzie to rozwiązanie.
W opozycji do powyższego stoi replikacja asynchroniczna, która nie daje pewności co do stanu serwerów zapasowych, ale nie ogranicza wydajności w tym samym stopniu. Informacja o zmianach jest przesyłana z serwera głównego do replik. Potwierdzenie z ich strony nie jest wymagane do pracy nad następnymi transakcjami. W przypadku awarii może to spowodować utratę pewnej części danych.
Kolejnym kryterium, według którego można spojrzeć na replikację, jest jej granularność. Korzystanie z części rozwiązań wiąże się koniecznością replikowania całego klastra, podczas gdy inne z nich pozwalają na kontrolę na poziomie poszczególnych relacji bądź baz danych.
Jakie rodzaje replikacji oferuje sam PostgreSQL?
Zanim przejdziemy do opisywania mechanizmów samego PostgreSQL, warto zwrócić uwagę na jeden istotny fakt wynikający z decyzji twórców Postgresa, aby nie implementować własnych mechanizmów do obsługi urządzeń dyskowych. Dzięki temu, że PostgreSQL przechowuje dane w plikach, można skorzystać z rozwiązań replikacji systemów plików, jak na przykład DRBD.
Co do mechanizmów samego Postgresa, skupimy się na dwóch najważniejszych sposobach:
- replikacja strumieniowa – wykorzystująca WAL (ang. Write Ahead Log) shipping, czyli możliwość przesyłania dzienników transakcji do serwerów pomocniczych, które na ich podstawie reprodukują zmiany z serwera głównego
- replikacja logiczna – dostępna od 10. wydania PostgreSQL, która dzięki dekodowaniu logicznemu pozwala na replikację wybranych zmian w poszczególnych bazach, tabelach lub innych logicznych obiektach znajdujących się w bazie (w odróżnieniu od binarnych zmian na całym klastrze znajdujących się w WAL).
W kontekście wcześniej wspomnianych podziałów replikacja logiczna pozwala na lepszą granularność. Może być jednak mniej wydajna niż replikacja strumieniowa, ze względu na dodatkową pracę wykonywaną przez serwer – dekodowanie logiczne. Obydwa rodzaje replikacji pozwalają na synchroniczne bądź asynchroniczne przesyłanie zmian.
Replikacja strumieniowa
Przyjrzyjmy się nieco dokładniej mechanizmom stojącym za replikacją strumieniową (ang. streaming replication). Serwer zapasowy w tym przypadku łączy się z serwerem głównym, który przesyła strumień zmian z dziennika zmian transakcji zaraz po ich wygenerowaniu. Domyślnie ten rodzaj replikacji jest asynchroniczny, co powoduje niewielkie opóźnienie pomiędzy zatwierdzeniem transakcji na masterze a ich pojawieniem się w standby.
Jednym z ważniejszych wyznaczników kondycji replikacji strumieniowej, zdecydowanie polecanym do monitorowania, jest liczba wygenerowanych rekordów WAL w serwerze głównym niezatwierdzonych jeszcze w serwerze zapasowym. Można łatwo policzyć tę różnicę. Funkcje, które to umożliwiają to pg_current_wal_lsn na serwerze głównym oraz pg_last_wal_receive_lsn na serwerze zapasowym. Ponadto warto zwrócić uwagę również na systemowy widok pg_stat_replication. Analiza różnic między pg_current_wal_lsn oraz kolumną sent_lsn pozwala zauważyć, np. duże obciążenie serwera głównego, który z tego powodu po prostu „nie daje rady” przesyłać zmian.
Replikacja logiczna
Replikacja logiczna w PostgreSQL działa w oparciu o model publish-subscribe. Oznacza to, że każdy węzeł PostgreSQL może działać jako „wydawca” (ang publisher) publikujący zmiany oraz jako „subskrybent” (ang. subscriber) otrzymujący zmiany od jakiegoś innego węzła. W tym modelu subskrybent ściąga zmiany przez połączenie się z wydawcą. Ze względu na swoją granularność replikacja logiczna pozwala na tworzenie skomplikowanych scenariuszy zgodnie z potrzebami:
- przesyłanie przyrostowo zmian w jednej bazie danych (lub jej części), na przykład na potrzeby stworzenia węzła „archiwum”
- połączenie wybranych danych z kilku baz danych w jednym węźle
- replikacja danych między głównymi wydaniami PostgreSQL
- replikacja danych między instancjami Postgresa na różnych platformach (np. Linux → Windows)
- stworzenie dostępu do zreplikowanych danych dla innej grupy użytkowników.
Natywnie replikacja logiczna pojawiła się dopiero w wersji 10 PostgreSQL, choć wiele rozwiązań komercyjnych, jak EuroDB, oferuje możliwość skorzystania z tej funkcji również w starszych wersjach, gdzie nie jest ona standardowo dostępna.
Podsumowanie
W tym artykule spojrzeliśmy z dość wysokiego poziomu na mechanizmy replikacji dostępne w PostgreSQL. Dzięki temu mamy bazę, na której będziemy mogli zobaczyć, jak w praktyce zestawić replikację pomiędzy dwoma serwerami na przykładzie EuroDB oraz jak monitorować jej stan. W następnych tekstach przyjrzymy się też narzędziom pozwalającym na wykrycie awarii serwera głównego oraz wypromowanie jednego z zapasowych do działania jako serwer główny.