
 2018-01-10
2018-01-10
Meltdown i Spectre – luka w procesorach Intel. Krótkie porównanie wydajności po instalacji łatek
2018 rok rozpoczął się w branży IT prawdziwym trzęsieniem ziemi. Wybuchła ogromna afera medialna w roli głównej z udziałem Intela. Specjaliści z Google odkryli bowiem dwie luki w konstrukcji większości procesorów wyprodukowanych po 2010 roku i sprzedawanych przez wspomnianą firmę. EuroLinux bardzo szybko zaimplementował jednak łatki zabezpieczające przed groźnymi lukami. Czy w jakikolwiek sposób wpływają one na wydajność systemu EuroLinux?
2018 rok rozpoczął się w branży IT prawdziwym trzęsieniem ziemi. Wybuchła ogromna afera medialna w roli głównej z udziałem Intela. Specjaliści z Google odkryli bowiem dwie luki w konstrukcji większości procesorów wyprodukowanych po 2010 roku i sprzedawanych przez wspomnianą firmę. EuroLinux bardzo szybko zaimplementował jednak łatki zabezpieczające przed groźnymi lukami. Czy w jakikolwiek sposób wpływają one na wydajność systemu EuroLinux?
O Meltdown i Spectre w ostatnim czasie napisało już pół Internetu. Temat jest bardzo nośny, niestety często także pełen nieścisłości. Mówiąc najprościej – meltdown pozwala na to, by niezidentyfikowany proces mógł bezproblemowo przedostać się do pamięci podręcznej naszego procesora. Z kolei Spectre pozwala na odczytanie tego, co znajduje się w pamięci. Obydwie luki mogą być dosyć groźne. Dlatego też firma EuroLinux w szybkim czasie zaimplementowała do swojego systemu zabezpieczające łatki.
Najpełniejszą stroną z informacjami dotyczącymi błędu jest oficjalna strona: https://meltdownattack.com.
Istnieje także repozytorium z programami będącymi Proof of Concept ataku – https://github.com/IAIK/meltdown.
Błędy posiadają nawet własne logo i można znaleźć oferty sprzedaży T-shirtów z nimi. Jednak to nie dzięki świetnej identyfikacji graficznej zostaną nam na dłużej w pamięci. Meltdown olbrzymie nagłośnienie zawdzięcza spadkowi wydajności oraz faktowi, że CEO Intela w ostatnim czasie pozbył się znacznych aktywów, a także fatalnemu zachowaniu inżynierów Intela, co bardzo celnie w swoim złośliwym stylu skomentował Linus Torvalds na listach mailingowych Kernela.
https://lkml.org/lkml/2018/1/3/797
On Wed, Jan 3, 2018 at 3:09 PM, Andi Kleen <[email protected]> wrote:
> This is a fix for Variant 2 in
> https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
>
> Any speculative indirect calls in the kernel can be tricked
> to execute any kernel code, which may allow side channel
> attacks that can leak arbitrary kernel data.Why is this all done without any configuration options?
A *competent* CPU engineer would fix this by making sure speculation
doesn’t happen across protection domains. Maybe even a L1 I$ that is
keyed by CPL.I think somebody inside of Intel needs to really take a long hard look
at their CPU’s, and actually admit that they have issues instead of
writing PR blurbs that say that everything works as designed... and that really means that all these mitigation patches should be
written with “not all CPU’s are crap” in mind.Or is Intel basically saying “we are committed to selling you shit
forever and ever, and never fixing anything”?Because if that’s the case, maybe we should start looking towards the
ARM64 people more.Please talk to management. Because I really see exactly two possibibilities:
– Intel never intends to fix anything
OR
– these workarounds should have a way to disable them.
Which of the two is it?
Linus
Pisanie o kompetentnych inżynierach i zobowiązaniu do sprzedawania produktów niskiej jakości na zawsze oraz nienaprawianiu nigdy niczego sprawiło, że musiałem czyścić monitor z porannej kawy.
Meltdown i Spectre wymusił na dostawcach największych rozwiązań chmurowych aplikowanie patchy, które spowalniają dostępne dla użytkowników maszyny wirtualne. Nie muszę chyba tłumaczyć, że jest to bardzo niekomfortowa sytuacja. Posiadając mocno obciążoną instancję w AWS przed łatką, po łatce jesteśmy zmuszeni na przejście na, z reguły, dwa razy droższą, mocniejszą maszynę.
W tym artykule postaram się przeprowadzić stosunkowo proste testy wydajnościowe w celu zbadania wpływu nowych poprawek na EuroLinuxa w wersji 7.
Status błędu w EuroLinuxie
W chwili obecnej zarówno EuroLinux 6, jak i 7 zawierają wersję jądra odporne na podane ataki. Jądro zostało dostarczone z dodatkową flagą `CONFIG_KAISER=y`. Łatki zostały zaimplementowane do pakietów EuroLinux w następującym czasie:
- Kernel – 04.01.2018 r. (Red Hat – 03.01.2018 r., Oracle – 04.01.2018 r.)
- Libvirt – 05.01.2018 r. (Red Hat – 04.01.2018 r., Oracle – 05.01.2018 r.)
- qemu-kvm – 05.01.2018 r. (Red Hat – 04.01.2018 r., Oracle – 04.01.2018 r.)
- dracut – 07.01.2018 r. (Red Hat – 04.01.2018 r., Oracle – 04.01.2018 r.)
Microsoft pachta całościowego do swojego systemu wydał 04.01.2018 r.
By zobaczyć konfigurację jądra, należy zajrzeć do pliku /boot/cofnig-$(wersja jądra). Załatane zostały także pakiety odpowiedzialne za wirtualizację (qemu-kvm, libvirt) oraz dracut.
Co istotne, błędy i dostępne do nich erraty nie są określane jako krytyczne (critical), lecz „tylko” ważne – important. Wynika to z faktu, iż atakujący potrzebuje dostępu do naszej maszyny, by przeprowadzić atak. Niestety dostępem w tym wypadku jest także posiadanie maszyny wirtualnej.
Jako że błąd jest wciąż świeży, a sprawa się rozwija możliwe, że w przyszłości ten akapit trzeba będzie uaktualnić o nowe informacje, co oczywiście odpowiednio zaznaczę :).
Maszyna testowa
Za maszynę testową posłużył mi mój, naprawdę kochany Thinkpad 430. Krótki rzut oka na podzespoły.
– CPU: i5-3320M
– Dysk (na testowanej ścieżce /): GoodRam Iridium PRO 480GB
– Pamięć: 12GB DDR3 pracujące z prędkością 1600 MHz
Nowa łatka ma w znaczący sposób uderzać w programy używające dużo wywołań systemowych. Jednym z typów wywołań są operacje na plikach. Programy wykonujące ich dużo (np. baza danych), powinny więc znacząco to odczuć. W związku z tym faktem osoby posiadające szybsze nośniki (np. na złączu NVMe) bardziej odczują „zalety” nowej łatki, gdyż stosunek pracy procesora do czekania na dane z dysku wypada niekorzystnie.
Metodyka pomiaru
System w żaden sposób nie był strojony (tuned) – posiada standardowe ustawienia jądra. Na systemie jest włączony SELinux.
System został uruchomiony na dwóch jądrach – jedno posiada najnowsze poprawki, drugie nie. Bonusem jest wyłączenie części opcji PTI (Page Table Isolation) (Meltdown) z pozostawieniem (Indirect Branch Restricted Speculation) i (Indirect Branch Prediction Barriers) (Spectre), ustawienia takie są domyślnymi ustawieniami na procesory AMD.
Do testowania wydajności systemu posłużył sysbench, który jest dostępny w EPEL. W celu zainstalowania go używamy:
sudo yum install -y sysbench:
Drugi test przeprowadzę na najnowszej wersji PostgreSQL – 10. Mógłbym co prawda użyć EuroDB, ale zależało mi na tym, by każdy zainteresowany mógł samodzielnie odtworzyć wyniki testu.
Udajemy się więc na stronę https://yum.postgresql.org/repopackages.php#pg10 i instalujemy odpowiednią paczkę (zawierającą informację dotyczącą repozytoriów).
Następnie instalujemy PostgreSQLa.
sudo yum install postgresql10 sudo /usr/pgsql-10/bin/postgresql-10-setup initdb sudo systemctl enable postgresql-10.service sudo systemctl start postgresql-10
Następnie tworzymy bazę danych dla pgbencha.
su - postgres psql create database pgbench; # Ta komenda w konsoli psql \q # ta też
Teraz nadszedł czas na inicjalizację bazy danych pgbencha. Tę operację także wykonujemy jako user postgres.
su - postgres /usr/pgsql-10/bin/pgbench -i -s 10 pgbench
Przełącznik „-i” mówi o inicjalizacji a „-s” o skali, jaką chcemy uzyskać.
Używane komendy
CPU x 3
sysbench cpu --cpu-max-prime=10000 run sysbench cpu --cpu-max-prime=20000 --threads=4 run sysbench cpu --cpu-max-prime=20000 --threads=16 run
RAM x 3
sysbench memory --memory-total-size=10G run sysbench memory --memory-total-size=40G run sysbench memory --memory-block-size=4K --memory-scope=global --memory-total-size=50G --memory-oper=read run sysbench memory --memory-block-size=4K --memory-scope=global --memory-total-size=50G --memory-oper=write run
FileIO x 1
sysbench --test=fileio --file-total-size=1G prepare sysbench fileio --file-total-size=1G --threads=4 --file-test-mode=rndrw --max-time=1200 --max-requests=0 run sysbench --test=fileio --file-total-size=1G cleanup
PGBENCH
# select only /usr/pgsql-10/bin/pgbench -S -t 100000 pgbench # 100000 selectów 1 klient /usr/pgsql-10/bin/pgbench -S -c 4 -t 100000 pgbench # 400000 selectów 4 klienci 4 watki /usr/pgsql-10/bin/pgbench -S -j 4 -c 4 -t 100000 pgbench # 400000 selectów 4 klienci 4 watki # tpcb-like /usr/pgsql-10/bin/pgbench -b tpcb-like -t 10000 pgbench # 100000 selectów 1 klient /usr/pgsql-10/bin/pgbench -b tpcb-like -c 4 -t 10000 pgbench # 40000 selectów 4 klienci 4 watki /usr/pgsql-10/bin/pgbench -b tpcb-like -j 4 -c 4 -t 10000 pgbench # 40000 selectów 4 klienci 4 watki
Został ustawiony target mutli-user. systemctl set-default multi-user.target.
Wykonanie
skrypt run.sh
#!/bin/bash
my_name='bench_1' # 1, 2, 3
mkdir $my_name
date
echo "Start CPU"
for i in {1..0}; do
sysbench cpu --cpu-max-prime=5000 run >> ${my_name}/cpu.1
sysbench cpu --cpu-max-prime=10000 --threads=4 run >> ${my_name}/cpu.2
sysbench cpu --cpu-max-prime=10000 --threads=16 run >> ${my_name}/cpu.3
done
echo "Start Memory"
for i in {1..0}; do
sysbench memory --memory-total-size=10G run >> ${my_name}/mem.1
sysbench memory --memory-total-size=40G run >> ${my_name}/mem.2
sysbench memory --memory-block-size=4K --memory-scope=global --memory-total-size=50G --memory-oper=read run >> ${my_name}/mem.3
sysbench memory --memory-block-size=4K --memory-scope=global --memory-total-size=50G --memory-oper=write run >> ${my_name}/mem.4
done
echo "START FILEIO"
sysbench --test=fileio --file-total-size=128M prepare > ${my_name}/fileio.1
sysbench fileio --file-total-size=128M --threads=4 --file-test-mode=rndrw --max-time=180 --max-requests=0 run > ${my_name}/fileio.2
sysbench --test=fileio --file-total-size=128M cleanup > ${my_name}/fileio.3
echo "START SELECT"
su postgres -c '/usr/pgsql-10/bin/pgbench -S -t 100000 pgbench' > ${my_name}/pg.1
su postgres -c '/usr/pgsql-10/bin/pgbench -S -c 4 -t 100000 pgbench' > ${my_name}/pg.2
su postgres -c '/usr/pgsql-10/bin/pgbench -S -j 4 -c 4 -t 100000 pgbench' > ${my_name}/pg.3
echo "START tpcb"
su postgres -c '/usr/pgsql-10/bin/pgbench -b tpcb-like -t 10000 pgbench' > ${my_name}/pg.4
su postgres -c '/usr/pgsql-10/bin/pgbench -b tpcb-like -c 4 -t 10000 pgbench' > ${my_name}/pg.5
su postgres -c '/usr/pgsql-10/bin/pgbench -b tpcb-like -j 4 -c 4 -t 10000 pgbench' > ${my_name}/pg.6
date
Wyniki
Ku mojemu zdumieniu tylko w przypadku testów postgresowych można zauważyć spadek wydajności. Nie jest on jednak tak spektakularny, jak się spodziewałem. Poniżej zamieszczam skrypt ze sczytanymi danymi i wygenerowane wykresy.
# testname_benchnumber
#CPU
cpu1_1 <- c(2754.89,2771.17,2776.88)
cpu1_2 <- c(2753.45,2764.65,2763.78)
cpu1_3 <- c(2759.46,2774.00,2773.67)
cpu1 <- c(mean(cpu1_1),mean(cpu1_2),mean(cpu1_3))
cpu2_1 <- c(2952.30,2951.21,2952.92)
cpu2_2 <- c(2950.72,2953.55,2953.84)
cpu2_3 <- c(2952.96,2951.82,2952.28)
cpu2 <- c(mean(cpu2_1),mean(cpu2_2),mean(cpu2_3) )
cpu3_1 <- c(2967.02,2967.88,2967.42)
cpu3_2 <- c(2966.89,2966.77,2967.64)
cpu3_3 <- c(2965.68,2966.15,2966.60)
cpu3 <- c(mean(cpu3_1),mean(cpu3_2),mean(cpu3_3) )
# MEM
mem1_1 <- c(4633546.67,4612254.62,4625537.77)
mem1_2 <- c(4503442.39,4550892.25,4550062.05)
mem1_3 <- c(4556019.26,4551395.38,4555740.97)
mem1 < c(mean(mem1_1),mean(mem1_2),mean(mem1_3) )
mem2_1 <- c(4443425.06,4634798.61,4637708.93)
mem2_2 <- c(4536877.33,4561183.67,4534956.31)
mem2_3 <- c(4556349.79,4559066.11,4550771.30)
mem2 <- c(mean(mem2_1),mean(mem2_2),mean(mem2_3) )
mem3_1 <- c(4170833.04,4001983.11,4187500.21)
mem3_2 <- c(3983233.58,4135204.33,4154492.55)
mem3_3 <- c(4146563.63,3986775.88,4152701.40)
mem3 <- c(mean(mem3_1),mean(mem3_2),mean(mem3_3) )
mem_4_1 <- c(2511290.19,2513708.55,2512041.11)
mem_4_2 <- c(2479849.53,2484226.63,2481916.47)
mem_4_3 <- c(2481839.50,2478594.53,2481912.26)
mem_4 <- c(mean(mem4_1),mean(mem4_2),mean(mem4_3) )
# FILEIO first one is bench_1 second is bench_2 etc.
reads_per_s <-c (1267.29, 1242.95, 1284.28)
writes_per_s <-c (844.86, 828.65, 856.19)
fsyncs_per_s <-c (2703.10, 2651.14, 2739.22)
pg_1 <- c(9807.743930, 9879.473226, 9466.316596)
pg_2 <- c(30847.651379, 30724.505662, 30058.210408)
pg_3 <- c(36914.843658, 36773.945451, 35758.956943)
pg_4 <- c(354.046591, 349.590370, 356.289145)
pg_5 <- c(736.258622, 738.021144, 735.160172)
pg_6 <- c(735.197540, 734.390789, 736.229064)
# Plots
barplot(cpu1, main="CPU Test 1", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Events per second")
barplot(cpu2, main="CPU Test 2", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Events per second")
barplot(cpu3, main="CPU Test 3", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Events per second")
barplot(mem1, main="Memory Test 1", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Operations per second")
barplot(mem2, main="Memory Test 2", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Operations per second")
barplot(mem3, main="Memory Test 3", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Operations per second")
barplot(mem4, main="Memory Test 4", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Operations per second")
# NOTE: Only one plot is needed results are symetrical.
barplot(reads_per_s, main="FileIO Test", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Reads per second")
barplot(writes_per_s, main="FileIO Test", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Writes per second")
barplot(fsyncs_per_s, main="FileIO Test", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="fsync() per second")
barplot(pg_1, main="PGBench Test 1", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
barplot(pg_2, main="PGBench Test 2", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
barplot(pg_3, main="PGBench Test 3", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
barplot(pg_4, main="PGBench Test 4", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
barplot(pg_5, main="PGBench Test 5", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
barplot(pg_6, main="PGBench Test 6", names.arg = c("Unpatched", "Patched-=TPI", "Patched"),
col=rainbow(3), ylab="Transaction per second")
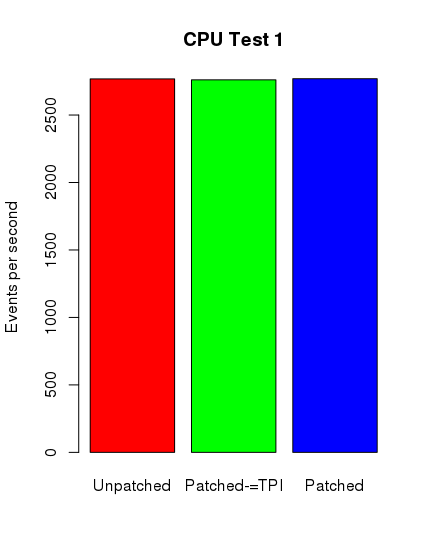
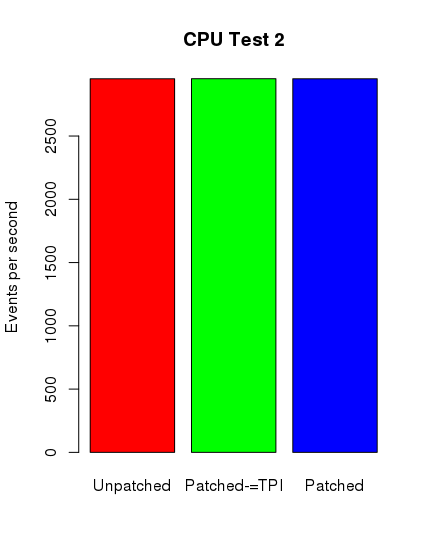
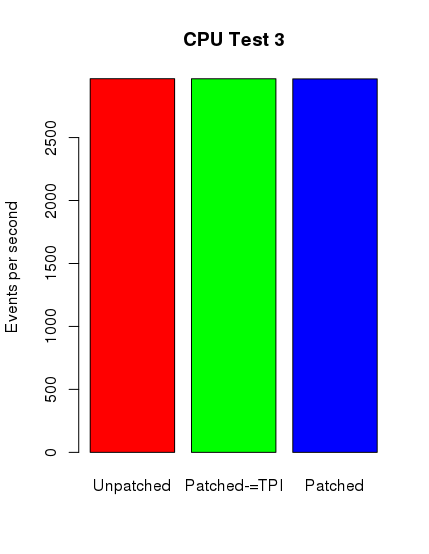
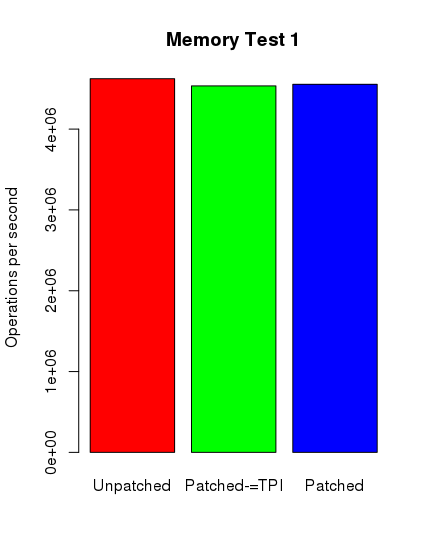

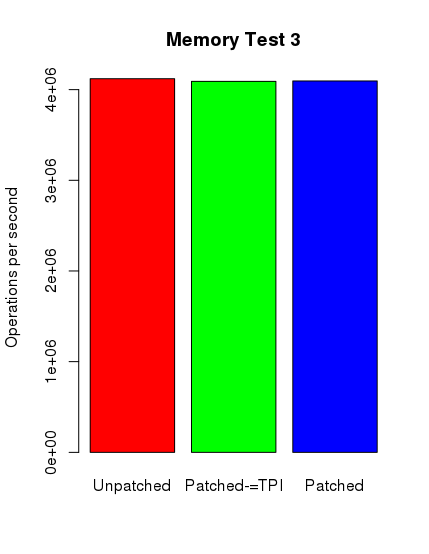
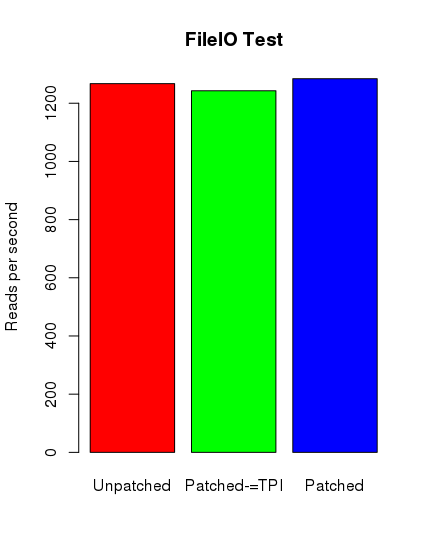



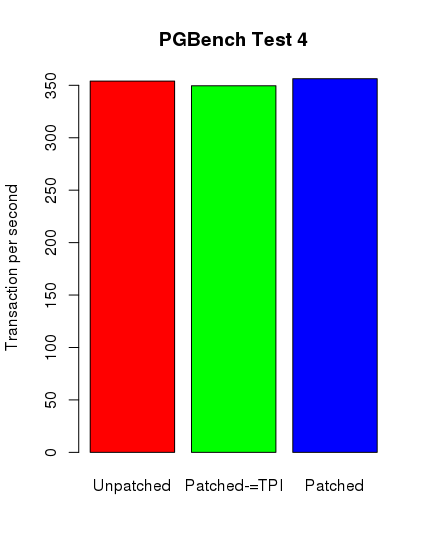
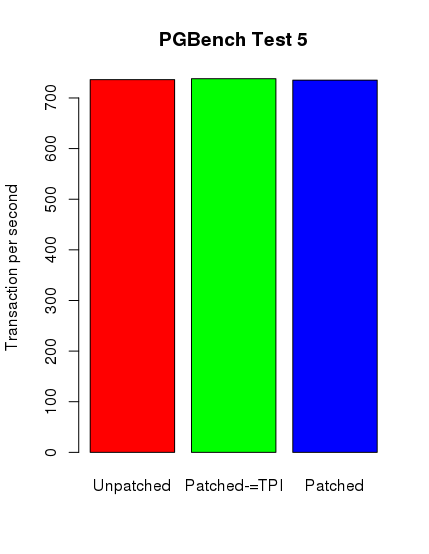
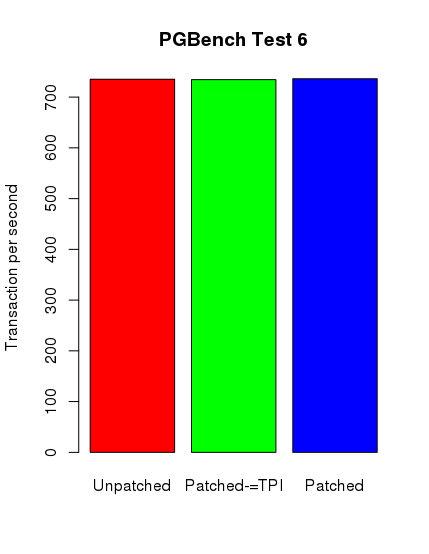 Środkowy słupek reprezentuje nowy kernel z wyłączonym pti, jednak z ibrs i ibpb.
Środkowy słupek reprezentuje nowy kernel z wyłączonym pti, jednak z ibrs i ibpb.
Jak widać, wyniki nie są tak szokujące, jak można było się spodziewać. W najbliższym czasie postaram się wykonać dodatkowe testy na innych maszynach z nowszymi podzespołami. Niemniej dziękuję Państwu za uwagę.