Przygotowaliśmy najobszerniejsze w całej sieci w języku polskim zestawienie zmian i nowych funkcjonalności w PostgreSQL 14. Jest to system do zarządzania obiektowo-relacyjnymi bazami danych. Mając za sobą ponad dwie dekady rozwoju, Postgres jest obecnie najbardziej zaawansowaną bazą danych typu Open Source, dostępną w każdym miejscu na świecie.
30 września 2021 roku została wydana najnowsza wersja PostgreSQL 14. Fani Postgresa mieli więc okazję do świętowania przez cały tydzień, gdyż 6 dni wcześniej miała miejsce pierwsza rocznica wydania wersji 13. Jest to zatem doskonała chwila, aby spojrzeć na zmiany, które twórcy topowego silnika bazodanowego przygotowali w bieżącej wersji. Słowem wstępu, wyjaśnijmy najpierw, czym jest PostgreSQL i jakie ma on znaczenie na obecnym rynku.
PostgreSQL to system do zarządzania obiektowo-relacyjnymi bazami danych, opracowany na Wydziale Informatyki Uniwersytetu Kalifornijskiego w Berkeley. Mając za sobą ponad dwie dekady rozwoju, PostgreSQL jest obecnie najbardziej zaawansowaną bazą danych typu Open Source, dostępną w każdym miejscu na świecie.
Krótka historia powstania
Projekt POSTGRES, prowadzony przez profesora Michaela Stonebrakera, był sponsorowany między innymi przez Agencję Zaawansowanych Projektów Badawczych w Obszarze Obronności – Defense Advanced Research Projects Agency (DARPA). Wdrażanie POSTGRESa rozpoczęło się w 1986 roku, a pierwsza działająca wersja demonstracyjna była już w roku 1987.
W 1994 roku Andrew Yu i Jolly Chen dodali do POSTGRESa interpreter języka SQL. Pod nową nazwą Postgres95 został udostępniony w sieci jako Open Source’owy potomek oryginalnego kodu POSTGRESa z Berkeley. Co ciekawe, kod Postgres95 był napisany całkowicie w standardzie ANSI C, został skrócony o 25%, a jego działanie było zaskakująco szybkie, bo aż około 30-50% szybsze w porównaniu z POSTGRES.
Na początku roku 1996 stało się jasne, że nazwa „Postgres95” nie przetrwa próby czasu, gdyż z roku na rok będzie się wydawała coraz bardziej przestarzała. Wybrano więc nową nazwę – PostgreSQL. Nazwa ta powstała, aby odzwierciedlić związek między oryginalnym POSTGRESem a nowszymi wersjami z SQL. Jako ciekawostkę warto dopowiedzieć, że twórcy rozpoczęli numerację od 6.0, umieszczając w poprzednich wersjach wcześniejsze wydania Postgres95, a w wersji pierwszej oryginalny projekt POSTGRESa z Berkeley.
Postgres czy PostgreSQL?
Wiele osób nadal określa PostgreSQL jako „Postgres” (teraz rzadko pisany wielkimi literami) ze względu na tradycję lub łatwiejszą wymowę. Użycie tej nazwy jest powszechnie akceptowane jako pseudonim lub alias.
PostgreSQL a pozycja na rynku
Według serwisu Google Trends popularność PostgreSQL (kolor niebieski) nieustannie rośnie. Mocno zwiększa się również jego przewaga względem innych znanych systemów zarządzania bazami danych, takich jak Oracle DB (kolor czerwony) czy MongoDB (kolor żółty).
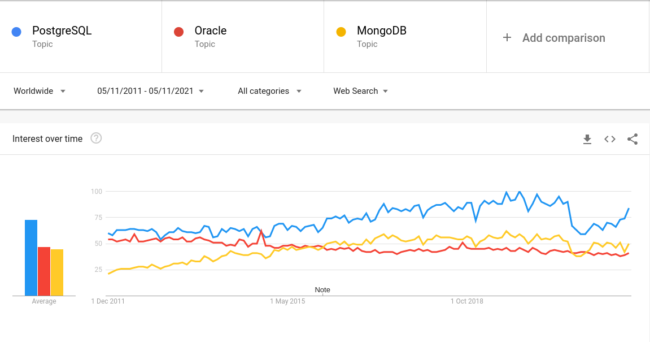 Wykres przedstawia zainteresowanie w czasie. Szczyt popularności frazy w wyszukiwaniach Google oznaczony został jako wartość 100. Wartość 50 oznacza że fraza była dwa razy mniej popularna.
Wykres przedstawia zainteresowanie w czasie. Szczyt popularności frazy w wyszukiwaniach Google oznaczony został jako wartość 100. Wartość 50 oznacza że fraza była dwa razy mniej popularna.
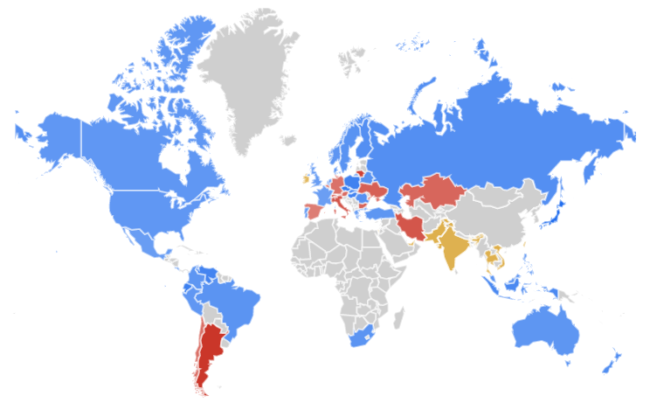
Mapa obrazuje popularność PostgreSQL (niebieski), Oracle DB (czerwony), MongoDB (żółty) na przestrzeni ostatnich 10 lat. Im ciemniejszy jest kolor tym większą ma przewagę w danym regionie. Kolor szary oznacza brak danych.
PostgreSQL 14 a PostgreSQL 13
Wersja 14 relacyjnej bazy danych PostgreSQL została wydana 30 września 2021 roku i posiada szereg nowości względem swojej poprzedniczki. Twórcy w najnowszej wersji Postgresa zauważalnie pochylili się nad względem wydajności bazy danych, nowym sposobem replikacji czy też trybem awaryjnym dla garbage-collectora. Są to jedynie przykłady nowych funkcjonalności, które znajdziemy w najnowszej wersji PostgreSQL 14. Obszerna lista wszystkich zmian dostępna jest poniżej.
Szczegółowa lista nowych funkcjonalności i zmian w PostgreSQL 14
Poniższa lista została podzielona na następujące kategorie tematyczne: Serwer, Replikacja strumieniowa i przywracanie, Klauzule SELECT i INSERT, Polecenia użytkowe, Typy danych, Funkcje, PL/PgSQL, Interfejs klienta, Aplikacje klienckie, Aplikacje serwera, Dokumentacja, Kod źródłowy oraz Dodatkowe moduły. Lista opisuje wszelkie zmiany w PostgreSQL 14 w stosunku do poprzedniego głównego wydania Postgresa.
Serwer
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano predefiniowane role pg_read_al_data i pg_write_al_data |
Role te mogą być użyte, aby zapewnić prawa odczytu i zapisu do wszystkich tabel, widoków i sekwencji bez konieczności logowania |
Stephen Frost |
| Dodano predefiniowaną rolę pg_database_owner, która określa właściciela bazy danych |
Jest to niezwykle przydatne do wykorzystania w template databases |
Noah Misch |
| Usunięto pliki temporalne po błędzie krytycznym |
Wcześniej pliki te zostawały w celach debugowania. W razie potrzeby funkcję tę można kontrolować nowym parametrem serwera remove_temp_files_after_crash |
Euler Taveira |
| Dodano możliwość przerwania długo działających zapytań, gdy następuje rozłączenie klienta |
Parametr serwera client_conection_check_interval pozwala kontrolować, czy utrata połączenia jest sprawdzana (wspierane na systemie Linux i kilku innych) |
Sergey Cherkashin, Thomas Munro |
| Dodano opcjonalny timeout pg_terminate_backend() |
– |
– |
| Zezwolono, aby szerokie krotki były dodawane do prawie pustych stron stosu |
Poprzednio krotki, których dodanie przekraczało współczynnik zajętości strony, były dodawane do nowych stron |
John Naylor, Floris van Ne |
| Dodano Server Name Indication (SNI) w pakietach połączenia SL |
Można to zablokować za pomocą opcji slsni |
Peter Eisentraut |
Serwer – vacuum
Vacuum to inna nazwa na Garbage-Collector, czyli narzędzie do zbierania i usuwania niepotrzebnych rzeczy (tak zwanych śmieci) z bazy danych np. martwych krotek.
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano możliwość pomijania przez vacuum czyszczenia indeksów, gdy liczba usuwalnych wpisów indeksów nie jest znacząca |
Parametr INDEX_CLEANUP ma nową wartość domyślną auto, która zezwala na tę optymalizację |
Masahiko Sawada, Peter Geoghegan |
| Umożliwiono bezpośrednie (bez wcześniejszego zaznaczenia, że strona jest usunięta) dodawanie przez vacuum usuniętych stron btre do mapy wolnego miejsca |
Wcześniej vacuum mógł dodawać do mapy wolnego miejsca jedynie te strony, które uprzednio były zaznaczone jako usunięte |
Peter Geoghegan |
| Dodano możliwość odzyskiwania przez vacuum miejsca użytego przez nieużywane wskaźniki stosu |
– |
Mathias van de Ment, Peter Geoghegan |
| Umożliwiono stosowanie przez vacuum bardziej agresywnej taktyki usuwania martwych rzędów podczas operacji indeksowania z minimalną blokadą |
CREATE INDEX CONCURENTLY i REINDEX CONCURENTLY nie są ograniczone przez usuwanie martwych rzędów innych relacji |
Álvaro Herera |
| Przyspieszono metody czyszczenia bazy danych z wieloma relacjami |
– |
Tatsuhito Kasahara |
| Usunięto wartości domyślne parametru vacuum_cost_page_mis, aby lepiej odzwierciedlić obecne możliwości sprzętowe |
– |
Peter Geoghega |
| Dodano możliwości pominięcia czyszczenia tabel TOAST |
Aktualnie VACUUM posiada opcję PROCES_TOAST, która ustawiona na false wyłącza czyszczenie tablicy TOAST. Dodatkowo do vacuumdb dodano opcję no-proces-toast |
Nathan Bosart |
| Poprawiono aktualizację bitów widoczności strony dla COPY FREZE |
– |
Anastasia Lubenikova, Pavan Deolase, Jef Janes |
| Umożliwiono operacjom czyszczącym bardziej agresywną taktykę, gdy tabela jest bliska zdarzenia xid lub multixact wraparound |
Jest to kontrolowane przez vacuum_failsafe_age u vacuum_multixact_failsafe_age |
Masahiko Sawada, Peter Geoghegan |
| Zwiększono czas ostrzeżenia i limit przed zdarzeniem transaction id i multi-transaction wraparound |
To powinno zredukować prawdopodobieństwo wystąpienia błędu bez żadnych ostrzeżeń odnośnie zdarzenia wraparound |
Noah Misch |
| Dodano informacje per-index do logów autovacuum |
– |
Masahiko Sawada |
Serwer – partycjonowanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Poprawiono wydajność aktualizowania i usuwania partycjonowanej tablicy z wieloma partycjami |
Ta zmiana znacząco redukuje obciążenie planisty, a także umożliwia aktualizację/usuwanie partycjonowanych tabel z użyciem execution-time partition pruning |
Amit Langote, Tom Lane |
| Dodano możliwość odłączania partycji w sposób nieblokujący |
Składnia to ALTER TABLE … DETACH PARTITION … CONCURRENTLY i FINALIZE |
Álvaro Herrera |
| Umożliwiono zignorowanie klauzuli COLLATE w wartościach granicznych partycjonowania |
Poprzednio takie klauzule musiały pasować do klucza partycji |
Tom Lane |
Serwer – indeksowanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono na dodawanie indeksowania btree w celu usunięcia wygaśniętych wpisów indeksu, aby zapobiec podziałom stron |
Jest to szczególnie przydatne przy zmniejszaniu przyrostu indeksów w tabelach, których indeksowane kolumny są często aktualizowane |
Peter Geoghegan |
| Zezwolono indeksom BRIN na rejestrowanie wielu wartości z zakresu min/max |
Jest to przydatne, jeżeli istnieją grupy wartości w każdym zakresie stron |
Tomas Vondra |
| Zezwolono indeksom BRIN na użycie filtrów bloom |
Pozwala to, aby indeksy BRIN były bardziej efektywne dla danych, które nie są dobrze zlokalizowane w stosie |
Tomas Vondra |
| Zezwolono, aby niektóre indeksy GiST były zbudowane przez wstępne sortowanie danych |
Wstępne sortowanie odbywa się automatycznie i pozwala na szybsze tworzenie mniejszych indeksów |
Andrey Borodin |
| Zezwolono, aby indeksy SP-GiST zawierały kolumny z klauzulą INCLUDE |
– |
Pavel Borisov |
Serwer – optymalizacja
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono na wyszukiwanie hasha dla klauzuli IN z wieloma stałymi |
Wcześniej kod zawsze skanował sekwencyjnie listę wartości |
James Coleman, David Rowley |
| Zwiększono liczbę obszarów wykorzystywanych do szacowania klauzuli OR |
– |
Tomas Vondra, Dean Rasheed |
| Zezwolono na używanie extended statistics w wyrażeniach |
Pozwala to na statystykę grup wyrażeń i kolumn zamiast tylko kolumn, jak w przeszłości. System pg_stats_ext_exprs raportuje takowe statystyki |
Tomas Vondra |
| Zezwolono na efektywne skanowanie stosu z przedziału TIDs |
Poprzednio w przypadku nierównych specyfikacji TDI było potrzebne skanowanie sekwencyjne |
Edmund Horner, David Rowley |
| Naprawiono EXPLAIN CREATE TABLE AS i EXPLAIN CREATE MATERIALIZED VIEW dla IF NOT EXISTS |
Poprzednio, jeżeli obiekt już istniał, EXPLAIN zwracał błąd |
Bharath Rupireddy |
Serwer – ogólna wydajność
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Przyspieszono przetwarzanie migawek widoczności MVCC w systemach z wieloma procesorami i dużą ilością sesji |
Poprawia to również wydajność, gdy mamy wiele bezczynnych sesji |
Andres Freund |
| Dodano metodę wywołania w celu zapamiętania wyników z wewnętrznej – zagnieżdżonej pętli joinów |
Jest to użyteczne, gdy mały procent wierszy jest zaznaczony ze strony wewnętrznej (inner side). Może być wyłączone przez parametr serwera enable_memoize |
David Rowley |
| Umożliwiono window functions wykonywanie sortowania przyrostowego |
– |
David Rowley |
| Poprawiono wydajności I/O dla równoległych skanowań sekwencyjnych |
Dokonano tego dzięki alokowaniu bloków w grupach do równoległych workerów |
Thomas Munro, David Rowley |
| Umożliwiono zapytaniu odwołującemu się do wielu tabel obcych równoległe skanowanie tabel obcych |
postgres_fdw wspiera tego typu skanowanie, jeżeli opcja async_capable jest włączona |
Robert Haas, Kyotaro Horiguchi, Thomas Munro, Etsuro Fujita |
| Umożliwiono analyze wstępne pobieranie stron |
Można to kontrolować za pomocą maintenance_io_concurrency |
Stephen Frost |
| Poprawiono wydajność wyszukiwania wyrażeń regularnych |
– |
Tom Lane |
| Znacząco poprawiono normalizację Unicode |
Przyśpiesza to funkcję normalize() i IS NORMALIZED |
John Naylor |
| Dodano możliwość użycia kompresji LZ4 na danych TOAST |
Może to być ustawione na poziomie kolumny lub domyślnie za pomocą parametru serwera default_toast_compression. Serwer musi być skompilowany z opcją –with-lz4, która wspiera tę funkcję. Domyślnym ustawieniem nadal jest pglz |
Dilip Kumar |
| Dodano funkcję, dzięki której, gdy parametr serwera compute_query_id jest włączony, wyświetlany jest id zapytania w pg_stat_activity, EXPLAIN VERBOSE, csvlog i opcjonalnie w log_line_prefix |
Id zapytania wytworzony przez rozszerzenie będzie również wyświetlony |
Julien Rouhaud |
| Poprawiono logi dla auto-vacuum i auto-analyze |
Gdy track_io_timing jest włączone, to raportuje czasy I/O dla auto-vacuum i auto-analyze. Ponadto zapisuje również odczyt bufora i współczynniki poprawności (dirty rates) dla auto-analyze |
Stephen Frost, Jakub Wartak |
| Dodano informację odnośnie oryginalnej nazwy użytkownika przekazanej przez klienta w log_connections |
– |
Jacob Champion |
Serwer – monitorowanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano funkcję, dzięki której, gdy parametr serwera compute_query_id jest włączony, wyświetlany jest id zapytania w pg_stat_activity, EXPLAIN VERBOSE, csvlog i opcjonalnie w log_line_prefix |
Id zapytania wytworzony przez rozszerzenie będzie również wyświetlony |
Julien Rouhaud |
| Poprawiono logi dla auto-vacuum i auto-analyze |
Gdy track_io_timing jest włączone, to raportuje czasy I/O dla auto-vacuum i auto-analyze. Ponadto zapisuje również odczyt bufora i współczynniki poprawności (dirty rates) dla auto-analyze |
Stephen Frost, Jakub Wartak |
| Dodano informację odnośnie oryginalnej nazwy użytkownika przekazanej przez klienta w log_connections |
– |
Jacob Champion |
Serwer – widoki
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano widok pg_stat_progress_copy, aby informować o postępie COPY |
– |
Josef Šimánek, Matthias van de Meent |
| Dodano widok pg_stat_wal, aby informować o aktywności WAL |
– |
Masahiro Ikeda |
| Dodano widok pg_stat_replication_slots, aby informować o aktywności slotów replikacji |
Funkcja pg_stat_reset_replication_slot() resetuje slot statystyczny |
Sawada Masahiko, Amit Kapila, Vignesh C |
| Dodano widok pg_backend_memory_contexts, aby informować o użyciu pamięci w sesji |
– |
Atsushi Torikoshi, Fujii Masao |
| Dodano funkcję pg_log_backend_memory_contexts(), aby wyświetlała kontekst pamięci dowolnego backendu |
– |
Atsushi Torikoshi |
| Dodano sekcję statystyk do widoku pg_stat_database |
– |
Laurenz Albe |
| Dodano kolumny do pg_prepared_statements, aby informować o liczbie ogólnych i niestandardowych planów |
– |
Atsushi Torikoshi, Kyotaro Horiguchi |
| Dodano czas oczekiwania na blokadę w pg_locks |
– |
Atsushi Torikoshi |
| Umożliwiono, aby proces archiwizacji był widoczny w pg_stat_activity |
– |
Kyotaro Horiguchi |
| Dodano event WalReceiverExit do informowania o czasie oczekiwania na zamknięcie WAL receivera |
– |
Fujii Masao |
| Zaimplementowano widok schematu informacyjnego routine_column_usage, aby śledzić kolumny, do których odwołują się funkcje i procedury domyślnych wyrażeń |
– |
Peter Eisentraut |
Server – autentykacja
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono dopasowanie wyróżniających nazw (DN) certyfikatów SSL na potrzeby autentykacji certyfikatu klienta |
Nowa opcja pg_hba.conf (clientname=DN) zezwala na porównanie z atrybutami certyfikatu poza CN i może być używana wraz z mapami identyfikującymi (ident maps) |
Andrew Dunstan |
| Zezwolono rekordom z pg_hba.conf i pg_ident.conf na zajmowanie wielu linii |
Znak “\” na końcu linii zezwala na kontynuowanie określania rekordu w następnej linii |
Fabien Coelho |
| Zezwolono na specyfikację katalogu dla listy odwołań certyfikatów (CRL) |
Jest to kontrolowane przez parametr serwera ssl_crl_dir i opcję połączenia libpq o nazwie sslcrldir |
Kyotaro Horiguchi |
| Zezwolono na hasła o dowolnej długości |
– |
Tom Lane, Nathan Bossart |
Server – konfiguracja serwera
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano parametr serwera idle_session_timeout w celu zamknięcia bezczynnych sesji |
Jest to podobne do idle_in_transaction_session_timeout |
Li Japin |
| Zmieniono domyślną wartość checkpoint_completion_target na 0.9 |
Poprzednio wynosiła ona 0.5 |
Stephen Frost |
| Zezwolono, aby %P w log_line_prefix informowało o PID lidera grupy równoległej dla równoległego workera |
– |
Justin Pryzby |
| Zezwolono na określanie wielu ścieżek oddzielonych przecinkami w unix_socket_directories. Każda ścieżka musi znajdować się w cudzysłowie |
– |
Ian Lawrence Barwick |
| Zezwolono na alokację dynamicznej pamięci współdzielonej przy uruchomieniu |
Kontrolowane jest to przez min_dynamic_shared_memory. Pozwala na lepsze wykorzystanie dużych stron |
Thomas Munro |
| Dodano parametr serwera huge_page_size w celu kontrolowania wielkości dużych stron używanych na Linuksie |
– |
Odin Ugedal |
Replikacja strumieniowa i przywracanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono serwerom standby synchronizację przez pg_rewind |
– |
Heikki Linnakangas |
| Zezwolono, aby ustawienia restore_command były możliwe do zmiany podczas reloadu serwera |
Można również ustawić restore_command na pusty string i zrobić reload serwera, aby wymusić odzyskiwanie tylko do odczytu z katalogu pg_wal |
Sergei Kornilov |
| Dodano parametr serwera log_recovery_conflict_waits, aby informować o długim czasie oczekiwania na konflikt podczas przywracania |
– |
Bertrand Drouvot, Masahiko Sawada |
| Dodano zatrzymanie odzyskiwania na serwerze w trybie gotowości, jeżeli serwer podstawowy zmieni swoje parametry w sposób uniemożliwiający odtwarzanie w tym trybie |
Poprzednio byłby zamykany natychmiastowo. |
Peter Eisentraut |
| Dodano funkcje pg_get_wal_replay_pause_state(), aby informować o statusie przywracania |
Daje to więcej szczegółowych informacji niż pg_is_wal_replay_paused() |
Dilip Kumar |
| Dodano nowy parametr tylko do odczytu dla serwera in_hot_standby |
Pozwala to klientom na łatwe wychwycenie, czy są połączeni do serwera hot standby |
Haribabu Kommi, Greg Nancarrow, Tom Lane |
| Przyspieszono obcinanie małych tabel podczas przywracania w klastrze z wieloma współdzielonymi buforami |
– |
Kirk Jamison |
| Umożliwiono synchronizację systemu plików na początku odzyskiwania po awarii w systemie Linux |
Domyślnie PostgreSQL synchronizuje każdy plik w klastrze w bazie danych na początku odzyskiwania po awarii. Po ustawieniu recovery_init_sync_method=syncfs odzyskiwane są natomiast wszystkie systemy plików. Pozwala to na szybsze odzyskanie danych na systemie z wieloma plikami bazy danych |
Thomas Munro |
| Dodano funkcję pg_xact_commit_timestamp_origin() w celu zwrócenia wartości timestampa commitu i pochodzenie replikacji określonej transakcji |
– |
Movead Li |
| Dodano informację o pochodzeniu replikacji do rekordu zwracanego przez pg_last_committed_xact() |
– |
Movead Li |
| Umożliwiono kontrolę funkcji pochodzenia replikacji przy pomocy standardowych zezwoleń funkcji |
Poprzednio tego typu funkcje mogły być wykonywane przez administratorów (superusers) i nadal jest to domyślnie ustawione |
Martín Marqués |
Replikacja strumieniowa i przywracanie – replikacja logiczna
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono replikacji logicznej strumieniowanie długich transakcji in-progress |
Poprzednio transakcje, które wykraczały poza logical_decoding_work_mem, były zapisywane na dysku do czasu, gdy transakcja nie dobiegła do końca |
Dilip Kumar, Amit Kapila, Ajin Cherian, Tomas Vondra, Nikhil Sontakke, Stas Kelvich |
| Poprawiono API replikacji logicznej, pozwalając strumieniować długie transakcje in-progress |
Funkcje wyjścia uruchamiane są wraz ze strumieniem. test_decoding jest również wspierane |
Tomas Vondra, Dilip Kumar, Amit Kapila |
| Zezwolono na tworzenie wielu transakcji podczas synchronizowania tablic w replikacji logicznej |
– |
Peter Smith, Amit Kapila, and Takamichi Osumi |
| Dodano natychmiastowe WAL-logi dla podtransakcji i wysoko-poziomowych powiązań XID |
Jest to przydatne do dekodowania logicznego |
Tomas Vondra, Dilip Kumar, Amit Kapila |
| Ulepszono logiczne dekodowanie API do obsługi commitów dwufazowych |
Kontroluje się to za pomocą pg_create_logical_replication_slot() |
Ajin Cherian, Amit Kapila, Nikhil Sontakke, Stas Kelvich |
| Dodano generowanie wiadomości o błędach WAL podczas wykonywania poleceń, gdy używana jest replikacja logiczna |
Gdy replikacja logiczna jest wyłączona, błędy WAL są generowane po zakończeniu transakcji. Pozwala to na logiczne strumieniowanie transakcji in-progress |
Dilip Kumar, Tomas Vondra, Amit Kapila |
| Poprawiono przetwarzanie cache’ów błędnych informacji podczas logicznego dekodowana |
Pozwala to na bardziej efektywne działanie logicznego dekodowania w obecności dużej ilości DDL |
Dilip Kumar |
| Umożliwiono kontrolę nad tym, czy wiadomości z logicznego dekodowania mają być wysłane do strumienia replikacji |
– |
David Pirotte, Euler Taveira |
| Umożliwiono subskrybentom logicznej replikacji używanie trybu transferu binarnego |
Jest on szybszy niż tryb tekstowy, ale nieco mniej stabilny |
Dave Cramer |
| Zezwolono, aby logiczne dekodowanie mogło być filtrowane przez XID |
– |
Markus Wanner |
Klauzule SELECT i INSERT
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zredukowano liczbę słów kluczowych, które nie mogą być użyte jako nazwa kolumn bez użycia AS |
Występuje teraz o 90% mniej zabronionych słów |
Mark Dilger |
| Umożliwiono tworzenie aliasów dla klauzuli JOIN USING |
Alias jest tworzony po wpisaniu AS tuż za klauzulą USING |
Peter Eisentraut |
| Umożliwiono dodanie klauzuli DISTINCT do GROUP BY w celu usunięcia duplikatów kombinacji GROUPING SET |
Na przykład GROUP BY CUBE (a,b), CUBE (b,c) wygeneruje duplikat kombinacji |
Vik Fearing |
| Poprawiono obsługę wpisów DEFAULT dla INSERT z wielowierszowymi listami VALUES |
Poprzednio często zwracało to błąd |
Dean Rasheed |
| Dodano klauzule SEARCH i CYCLE zgodne ze standardem SQL dla typowych wyrażeń tabelowych |
Te same wyniki można osiągnąć przy użyciu istniejącej składni, ale znacznie mniej wygodnie |
Peter Eisentraut |
| Umożliwiono nazwom kolumn w klauzuli WHERE ON CONFLICT być table-qualified |
Można jednak odwoływać się tylko do tabeli docelowej |
Tom Lane |
Polecenia użytkowe
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono REFRESH MATERIALIZED VIEW używanie równoległości |
– |
Bharath Rupireddy |
| Umożliwiono REINDEX zmianę przestrzeni tablicy (tablespace) nowego indeksu |
Zrobiono to dzięki dodaniu klauzuli TABLESPACE. Opcja –tablespace jest również dodana do reindexdb |
Alexey Kondratov, Michael Paquier, Justin Pryzby |
| Umożliwiono REINDEX przetwarzanie wszystkich potomnych tablic i indeksów relacji partycjonowanej |
– |
Justin Pryzby, Michael Paquier |
| Dodano komendy indeksowania używając CONCURRENTLY, aby zapobiegać oczekiwaniu na zakończenie innych operacji używających CONCURRENTLY |
– |
Álvaro Herrera |
| Poprawiono wydajność metody COPY FROM w trybie binarnym |
– |
Bharath Rupireddy, Amit Langote |
| Zachowano standardową składnię SQL dla funkcji w definicjach widoku |
Poprzednio wywołanie standardowej funkcji SQL, takiej jak EXTRACT(), było pokazane w zwykłej składni wywołania funkcji |
Tom Lane |
| Dodano w standardzie SQL klauzulę GRANTED BY, aby wykonać GRANT i REVOKE |
– |
Peter Eisentraut |
| Dodano opcję OR REPLACE dla CREATE TRIGGER |
Pozwala to na warunkowe zastąpienie istniejących już triggerów |
Takamichi Osumi |
| Umożliwiono TRUNCATE operowanie na tabelach obcych |
Moduł postgres_fdw również to wspiera |
Kazutaka Onishi, Kohei KaiGai |
| Ułatwiono dodawane i usuwane publikacji z subskrypcji |
Nowa składnia to ALTER SUBSCRIPTION … ADD/DROP PUBLICATION. Pozwala to uniknąć konieczności określania wszystkich publikacji w celu dodania/usunięcia wpisów |
Japin Li |
| Dodano klucze główne i obce wraz ze stałymi do katalogów systemowych |
Zmiana ta pomaga narzędziom GUI analizować katalogi systemowe. Istniejące unikalne indeksy katalogów mają teraz skojarzone stałe UNIQUE lub PRIMARY KEY. Relacje kluczy obcych nie są aktualnie przechowywane jako stałe, ale mogą być wyświetlone za pomocą funkcji pg_get_catalog_foreign_keys() |
Peter Eisentraut |
| Zezwolono na akceptację CURRENT_ROLE w każdym miejscu, gdzie jest akceptowany CURRENT_USER |
– |
Peter Eisentraut |
Typy danych
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono rozszerzeniom i wbudowanym typom danych używanie indeksów |
Poprzednio używanie indeksów musiało być hardkodowane w serwer i mogło być używane jedynie do typów tablicowych |
Dmitry Dolgov |
| Zezwolono na indeksy JSONB |
Indeksy JSONB mogą być użyte do znalezienia i przydzielenia części dokumentów JSONB |
Dmitry Dolgov |
| Dodano wsparcie dla wielozakresowych typów danych |
Są one podobne do zakresu typów danych, ale zezwalają na określenie wielu uporządkowanych zbiorów rozłącznych. Powiązany typ wielozakresowy jest tworzony automatycznie dla każdego typu zakresu |
Paul Jungwirth, Alexander Korotkov |
| Dodano obsługę języka ormiańskiego, baskijskiego, katalońskiego, hindi, serbskiego i jidysz |
– |
Peter Eisentraut |
| Umożliwiono plikom tsearch posiadanie nielimitowanej długości linii |
Poprzedni limit był ustawiony na 4KB. Dodatkowo usunięto funkcję t_readline() |
Tom Lane |
| Dodano wsparcie dla wartości numerycznych Infinity i -Infinity |
Dla danych typu Float są one już wspierane |
Tom Lane |
| Dodano operatory <<| i |>> reprezentujące ściśle powyżej/poniżej testów |
Poprzednio były nazywane >^ i <^, ale to nazewnictwo jest niezgodne z innymi typami danych geometrycznych. Stare nazwy pozostały dostępne, ale kiedyś mogą zostać usunięte |
Emre Hasegeli |
| Wprowadzono operatory do dodania i odjęcia wartości LSN oraz numerycznej |
– |
Fujii Masao |
| Binarny transfer danych jest teraz mniej restrykcyjny dla niezgodności tablic i rekordów OID |
– |
Tom Lane |
| Dodano możliwość tworzenia złożonych typów tablic dla katalogów systemowych |
Relacje zdefiniowane przez użytkownika od dawna mają powiązane typy złożone, a także typy tablicowe nad tymi typami złożonymi. Katalogi systemowe działają teraz na tej samej zasadzie. Ta zmiana rozwiązuje niespójności polegające na tym, że tworzenie tabeli zdefiniowanej przez użytkownika w trybie jednego użytkownika nie powodowałoby utworzenia typu tablicy złożonej |
Wenjing Zeng |
Funkcje
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono funkcjom i procedurom języka SQL używanie standardowego ciała funkcji SQL (SQL-standard function bodies) |
Poprzednio tylko ciała funkcji typu string były wspierane. Kiedy pisze się funkcję bądź procedurę w standardzie SQL, ciało jest parsowane natychmiastowo i przechowywane jako parse tree. Pozwala to na lepsze śledzenie zależności funkcji i może przynieść korzyści w zakresie bezpieczeństwa |
Peter Eisentraut |
| Umożliwiono procedurom posiadanie parametru OUT |
– |
Peter Eisentraut |
| Umożliwiono niektórym tablicom funkcji działanie na kilku kompatybilnych typach danych |
Funkcje array_append(), array_prepend(), array_cat(), array_position(), array_positions(), array_remove(), array_replace() i width_bucket() przyjmują teraz argumenty anycompatiblearray zamiast anyarray. Oznacza to, że są mniej restrykcyjne w kwestii dopasowań typów argumentów |
Tom Lane |
| Dodano funkcję trim_array(), która jest zgodna ze standardem SQL |
Można to już zrobić za pomocą wycinków tablicy, ale jest to trudniejsze |
Fearing |
| Dodano bajtowe odpowiedniki dla ltrim() i rtrim() |
– |
Joel Jacobson |
| Dodano wsparcie negatywnych indeksów w split_part() |
Negatywne wartości zaczynają się od ostatniego pola i liczą wstecz |
Nikhil Benesch |
| Wprowadzono nową funkcję string_to_table(), aby rozdzielić string pewnymi ogranicznikami |
Jest to podobne do funkcji regexp_split_to_table() |
Pavel Stehule |
| Dodano funkcję unistr(), aby zezwolić na tworzenie znaków Unicode w stringu poprzez wpisanie ukośnika wstecznego z numerem w notacji szesnastkowej |
Podobnie można określać Unicode w stringach literalnych (literal strings) |
Pavel Stehule |
| Dodano funkcję agregującą bit_xor() |
– |
Alexey Bashtanov |
| Wprowadzono funkcję bit_count(), która zwraca ilość włączonych(set) bitów w stringu bitów lub bajtów |
– |
David Fetter |
| Dodano funkcję date_bin() |
Ta funkcja grupuje wejściowe timestampy w interwały o jednakowej długości, dopasowane do określonego początku |
John Naylor |
| Umożliwiono make_timestamp()/make_timestamptz() akceptację minusowych wartości roku |
Minusowe wartości są interpretowane jako lata P.N.E. |
Peter Eisentraut |
| Zmieniono wyrażenie regularne substring() |
Poprawione wyrażenie zgodne ze standardem SQL ma następującą składnię: SUBSTRING(tekst SIMILAR wzór ESCAPE znak-ucieczki). Poprzednia składnia wyglądała następująco: SUBSTRING(tekst FROM wzór FOR znak-ucieczki). Jest ona nadal akceptowalna przez PostgreSQL |
Peter Eisentraut |
| Umożliwiono ucieczkę znaków \D, \S i \W wewnątrz nawiasów wyrażeń regularnych |
– |
Tom Lane |
| Dodano wyrażenie regularne [[:word:]], które jest równoważne do \w |
– |
Tom Lane |
| Umożliwiono/dodano wartościom domyślnym funkcji lead() i lag() dla window functions większą elastyczność typów danych |
– |
Vik Fearing |
| Każda niezerowa wartość Float dzielona przez Infinity zwraca teraz zero |
Poprzednio takie operacje zwracały błąd |
Kyotaro Horiguchi |
| NaN dzielone przez zero zwraca teraz wartość NaN |
Poprzednio takie operacje zwracały błąd |
Tom Lane |
| Wywołanie exp() i power() dla -Infinity zwraca teraz zero |
Poprzednio takie operacje zwracały błąd |
Tom Lane |
| Poprawiono dokładność obliczeń geometrycznych z wykorzystaniem nieskończoności |
– |
Tom Lane |
| Oznaczono wbudowane funkcje przymusu (coercion functions) bezpieczne(leakproof) |
Pozwala to na większe wykorzystanie funkcji wymagających konwersji typu w sytuacjach wrażliwych na bezpieczeństwo |
Tom Lane |
| Zmieniono pg_describe_object(), pg_identify_object() i pg_identify_object_as_address(), aby zawsze informowały o błędach dotyczących nieistniejących obiektów |
– |
Michael Paquier |
PL/pgSQL
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Poprawiono parsowanie wyrażeń i przypisań PL/pgSQL |
Pozwala to na przypisanie do wycinków tablicy i zagnieżdżonych pól rekordów |
Tom Lane |
| Umożliwiono uruchamianie zapytań RETURN QUERY równolegle w plpgsql |
– |
Tom Lane |
| Poprawiono wydajność powtarzalnych wywołań CALL w ramach procedur plpgsql |
– |
Pavel Stehule, Tom Lane |
Interfejs klienta
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano tryb potoku do libpq |
Pozwala to na wysłanie wielu zapytań oczekujących na zakończenie tylko wtedy, gdy zostanie wysłana określona wiadomość synchronizacyjna |
Craig Ringer, Matthieu Garrigues, Álvaro Herrera |
| Ulepszono opcję parametru target_session_attrs w libpq |
Nowe opcje to read-only, primary, standby i prefer-standby |
Haribabu Kommi, Greg Nancarrow, Vignesh C, Tom Lane |
| Poprawiono format outputu libpq PQtrace() |
– |
Aya Iwata, Álvaro Herrera |
| Dodano możliwość powiązania identyfikatora ECPG SQL z określonym połączeniem |
Zrobiono to dzięki DECLARE … STATEMENT |
Hayato Kuroda |
Aplikacje klienta
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono vacuumdb omijanie indeksów cleanup i truncation |
Opcje są następujące: –no-index-cleanup –no-truncate. |
Nathan Bossart |
| Umożliwiono pg_dump zgrywanie jedynie niektóre rozszerzeń |
Jest to kontrolowane przez opcję –extension |
Guillaume Lelarge |
| Do pgbench dodano funkcję permute(), która losowo zamienia wartości |
– |
Fabien Coelho, Hironobu Suzuki, Dean Rasheed |
| Dodano możliwość podglądu czasu odłączenia (disconnection times) podczas ponownego połączenia (reconnection overhead) w pgbench, wykorzystując przełącznik -C |
– |
Yugo Nagata |
| Umożliwiono użycie wielokrotnego -v w celu zwiększenia szczegółowości informacji |
Jest to wspierane przez pg_dump, pg_dumpall i pg_restore |
Tom Lane |
Aplikacje klienta – psql
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| W psql umożliwiono poleceniom \df i \do określanie typów argumentów funkcji i operatorów |
Pomaga to zredukować liczbę wyświetlanych dopasowań |
Greg Sabino Mullane, Tom Lane |
| Dodano metodę dostępu do kolumny w psql \d – + |
– |
Georgios Kokolatos |
| W psql umożliwiono poleceniom \dt i \di wyświetlanie tablic TOAST i ich indeksów |
– |
Justin Pryzby |
| Dodano do psql nową komendę \dX, która listuje obiekty potrzebne statystycznie (extended statistics) |
– |
Tatsuro Yamada |
| Naprawiono psql-ową komendę /dT, aby rozumiała składnię tablic i aliasy gramatyczne, takie jak int dla intigera |
– |
Greg Sabino Mullane, Tom Lane |
| Podczas edycji poprzedniego zapytania lub pliku z \e psql lub przy użyciu \ef lub \ev i jeśli edytor ma zakończyć działanie bez zapisywania, to jego wyniki będą zignorowane |
Wcześniej takie edycje ładowały poprzednie zapytanie do bufora zapytań i zazwyczaj wykonywały je natychmiast. Uznano, że prawdopodobnie nie jest to to, czego chce użytkownik |
Laurenz Albe |
| Poprawiono uzupełnianie etykiet |
– |
Vignesh C, Michael Paquier, Justin Pryzby, Georgios Kokolatos, Julien Rouhaud |
Aplikacje serwera
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano narzędzie wiersza poleceń pg_amcheck, aby uprościć uruchamianie testów contrib/amcheck na wielu relacjach |
– |
Mark Dilger |
| Dodano opcję –no-instructions do initdb |
Powoduje to pominięcie instrukcji uruchamiania serwera, które są normalnie wyświetlane |
Magnus Hagander |
| Zmieniono zachowanie pg_upgrade, aby zatrzymywał działanie przed tworzeniem skryptu analyze_new_cluster |
Zamiast tego podaje porównywalne instrukcje vacuumdb |
Magnus Hagander |
| Usunięto wsparcie dla opcji postmaster -o |
Było to niepotrzebne, ponieważ wszystkie przekazane opcje można było już określić bezpośrednio |
Magnus Hagander |
Dokumentacja
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zmieniono nazewnictwo „Default Roles” na „Predefined Roles” |
– |
Bruce Momjian, Stephen Frost |
| Dodano dokumentację dla funkcji factorial() |
Wraz z usunięciem operatora ! w tym wydaniu funkcja factorial() jest jedynym wbudowanym sposobem obliczania silni |
Peter Eisentraut |
Kod źródłowy
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano opcję konfiguracyjną –with-ssl={openssl}, aby umożliwić przyszły wybór biblioteki SSL |
Opcja –with-openssl jest dostępna w celach kompatybilności |
Daniel Gustafsson, Michael Paquier |
| Dodano wsparcie dla abstrakcyjnych gniazd w domenie Unix |
Aktualnie jest to wspierane na systemie Linux i Windows |
Peter Eisentraut |
| Umożliwiono systemowi Windows poprawną obsługę plików większych niż 4 GB |
Pozwala to na przykład na COPY plików WAL, a pliki segmentów relacji mogą być większe niż 4 GB |
Juan José Santamaría Flecha |
| Dodano parametr serwera debug_discard_caches w celu kontroli czyszczenia cache’a w celach testowych |
Poprzednio takie zachowanie można było ustawić jedynie w czasie kompilacji. Aby wywołać je podczas initdb, należy użyć nowej opcji –discard-caches. |
Craig Ringer |
| Dodano różne ulepszenia w wykrywaniu błędów w valgrind |
– |
Álvaro Herrera, Peter Geoghegan |
| Dodano moduł testowy dla pakietów wyrażeń regularnych |
– |
Tom Lane |
| Dodano wsparcie dla LLVM w wersji 12 |
– |
Andres Freund |
| Zmieniono SHA1, SHA2 i MD5, aby używały OpenSSL EVP API |
Jest to bardziej nowoczesne i wspiera tryb FIPS |
Michael Paquier |
| Usunięto osobną kontrolę czasu kompilacji podczas wyboru generatora liczb losowych |
Teraz jest to wybierane przy pomocy biblioteki SSL |
Daniel Gustafsson |
| Dodano bezpośrednią konwersję między kodowaniem EUC_TW i Big5 |
– |
Heikki Linnakangas |
| Dodano sortowanie wersji dla FreeBSD |
– |
Thomas Munro |
| Dodano dostęp amadjustmembers do API dostępu indeksów (index access method API) |
Umożliwia to sprawdzenie poprawności podczas tworzenia nowego operatora klasy czy operatora rodziny |
Tom Lane |
| Wprowadzono makra testowania funkcji libpq-fe.h dla ostatnio dodanych funkcji libpq |
W przeszłości aplikacje zwykle używały sprawdzenia w czasie kompilacji PG_VERSION_NUM w celu sprawdzenia, czy funkcja jest dostępna. Ale zwykle jest to wersja serwera, która niekoniecznie będzie zgodna z wersją libpq. libpq-fe.h oferuje symbole #define oznaczające funkcje widoczne dla aplikacji, a dodane w wersji v14. Celem jest dalsze dodawanie symboli dla takich funkcji w przyszłych wersjach |
Tom Lane, Álvaro Herrera |
Dodatkowe moduły
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono indeksowanie wartości hstore |
– |
Tom Lane, Dmitry Dolgov |
| Umożliwiono indeksom GiST/GIN pg_trgm wyszukiwanie równości |
Jest to podobne do LIKE z wyjątkiem działania symboli wieloznacznych |
Julien Rouhaud |
| Typ danych Cube może być przesyłany w trybie binarnym |
– |
KaiGai Kohei |
| Umożliwiono raportowanie pgstattuple_approx() w tabelach TOAST |
– |
Peter Eisentraut |
| Dodano moduł pg_surgery pozwalający na zmianę widoczności wiersza |
Jest przydatny podczas korygowania uszkodzeń bazy |
Ashutosh Sharma |
| Dodano moduł old_snapshot informujący o mapowaniu XID/time wykorzystywanym przez aktywny old_snapshot_threshold |
– |
Robert Haas |
| Umożliwiono amcheck sprawdzanie strony stosu |
Poprzednio sprawdzane były jedynie strony indeksów B-Tree |
Mark Dilger |
| Umożliwiono pageinspect sprawdzanie indeksów GiST |
– |
Andrey Borodin, Heikki Linnakangas |
| Numery bloku pageinspect stały się typami Bigint |
– |
Peter Eisentraut |
| Oznaczono funkcje btree_gist jako bezpieczne do zrównoleglania |
– |
Steven Winfield |
Dodatkowe moduły – pg_stat_statements
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Przeniesiono obliczanie hash’a zapytania z pg_stat_statements na rdzeń serwera |
Domyślna wartość ‘auto’ nowego parametru serwera compute_query_id włącza automatyczne obliczenia id zapytania podczas ładowania tego rozszerzenia |
Julien Rouhaud |
| pg_stat_statements śledzi instrukcje top i nested oddzielnie |
Wcześniej wszystkie instrukcje były śledzone jednocześnie i dawały pojedynczy output. Bardziej przydatne jest oddzielenie tych funkcji |
Julien Rohaud |
| Dodano liczbę wierszy dla poleceń użytkowych w pg_stat_statements |
– |
Fujii Masao, Katsuragi Yuta, Seino Yuki |
| Dodano widok do pg_stat_statements_info, aby ukazać aktywność pg_stat_statements |
– |
Katsuragi Yuta, Yuki Seino, Naoki Nakamichi |
Dodatkowe moduły – postgres_fdw
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono postgres_fdw zbiorczy INSERT wierszy |
– |
Takayuki Tsunakawa, Tomas Vondra, Amit Langote |
| Umożliwiono postgres_fdw importowanie partycji tabeli, jeżeli było to określone przez IMPORT FOREIGN SCHEMA … |
Domyślnie importowany jest jedynie katalog główny tabeli partycjonowanej |
Matthias van de Meent |
| Dodano funkcję postgres_fdw_get_connections() do postgres_fdw w celu informowania o otwartych połączeniach do obcego serwera |
– |
Bharath Rupireddy |
| Umożliwiono kontrolę nad tym, czy obce serwery utrzymują otwarte połączenia po zakończeniu transakcji |
Jest to kontrolowane przez keep_connections i domyślnie jest włączone |
Bharath Rupireddy |
| W razie potrzeby można teraz ponownie nawiązać połączenie do obcych serwerów |
Poprzednio restart obcego serwera mógł powodować błędy dostępu |
Bharath Rupireddy |
| Dodano funkcjonalność odrzucenia połączeń trzymanych w cache’u |
– |
Bharath Rupireddy |
Dalszy rozwój
Powyższa lista nowych funkcjonalności w PostgreSQL świadczy o stałym rozwoju i zaangażowaniu wielu społeczności, których celem jest tworzenie najlepszego oraz najszybszego silnika bazy danych. Z radością będziemy obserwować kolejne lata rozwoju Postgresa i informować Was o wszelkich nowościach.

 2021-11-08
2021-11-08
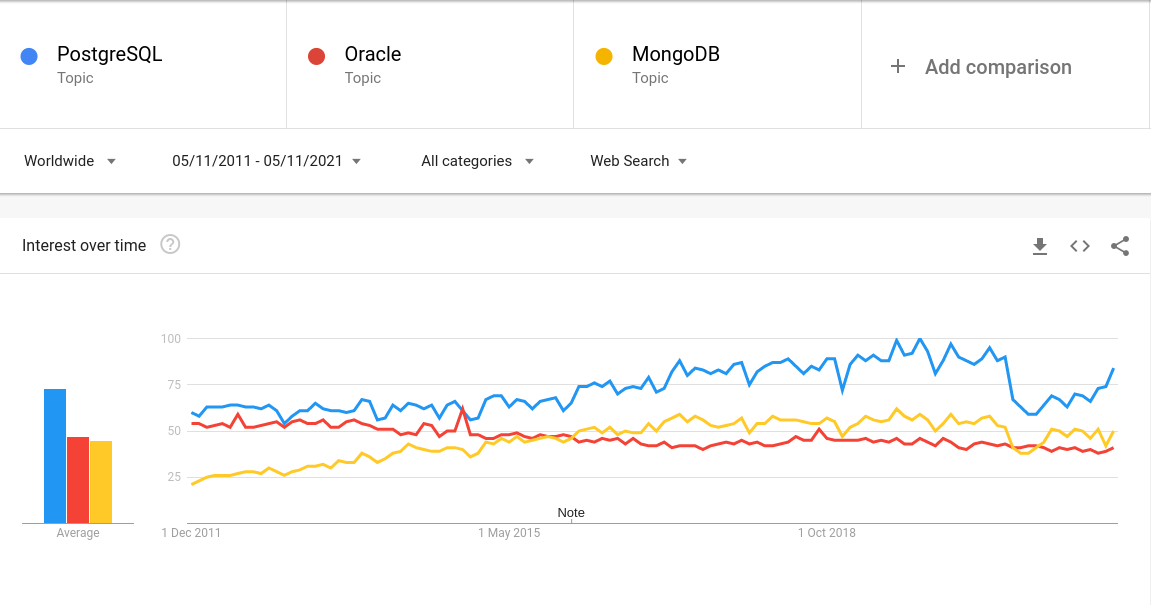 Wykres przedstawia zainteresowanie w czasie. Szczyt popularności frazy w wyszukiwaniach Google oznaczony został jako wartość 100. Wartość 50 oznacza że fraza była dwa razy mniej popularna.
Wykres przedstawia zainteresowanie w czasie. Szczyt popularności frazy w wyszukiwaniach Google oznaczony został jako wartość 100. Wartość 50 oznacza że fraza była dwa razy mniej popularna.