13 października 2022 roku zespół PostgreSQL Global Development Group opublikował najnowszą wersję wyczekiwanego silnika bazodanowego PostgreSQL 15. Jest to zatem dobra okazja do bliższego poznania najświeższego produktu, porównując go do poprzedniej wersji. Standardowo, sprawdzimy również aktualną pozycję PostgreSQL na rynku.
13 października 2022 roku zespół PostgreSQL Global Development Group opublikował najnowszą wersję wyczekiwanego silnika bazodanowego PostgreSQL 15. Jest to zatem dobra okazja do bliższego poznania najświeższego produktu, porównując go do poprzedniej wersji. Standardowo, sprawdzimy również aktualną pozycję PostgreSQL na rynku.
PostgreSQL to system do zarządzania obiektowo-relacyjnymi bazami danych. Umożliwia przechowywanie danych w postaci tabeli z wieloma relacjami oraz równoczesną manipulację nimi przy pomocy języka SQL. PostgreSQL został opracowany na Wydziale Informatyki Uniwersytetu Kalifornijskiego w Berkeley. Mając za sobą ponad dwie dekady rozwoju, jest obecnie najbardziej zaawansowaną bazą danych typu Open Source. Więcej informacji na temat historii Postgresa, a także o sporze użytkowników między nazwą PostgreSQL a Postgres, można znaleźć w naszym artykule, w którym szczegółowo omówiliśmy zmiany w PostgreSQL 14.
Kulisy powstania Postgresa 15
Obserwując na bieżąco zmagania twórców z napotykanymi problemami przy wersjach beta, można wysunąć wniosek, że w PostgreSQL 15 było sporo do poprawy. Najświeższy Postgres rzeczywiście doczekał się aż 4 wersji beta i 2 RC (Release Candidate). Nie świadczy to bynajmniej o braku kompetencji twórców, a wręcz przeciwnie – zmaganie się z tak wielkim projektem, obarczone jest występowaniem pewnych wyzwań, które twórcy nieustannie rozwiązują. W tym samym czasie wielu użytkowników testuje na własnym środowisku działanie kolejnych wersji, zgłaszając nowe, często bardzo zawikłane błędy. Stąd też składamy zasłużone gratulacje i życzymy chwili odpoczynku.
Pozycja PostgreSQL na rynku
Serwis Google Trends po raz kolejny posłuży nam do weryfikacji popularności PostgreSQL (kolor niebieski) względem rywali. Na wykresie można zauważyć początek światowej pandemii pod koniec roku 2020. To okres, w którym wyniki wyszukiwania drastycznie się obniżyły, żeby znów poszybować w górę w styczniu 2022. Mogło to być spowodowane powstaniem wielu firm sprzedających swoje produkty w internecie. Konkurencyjna baza danych Oracle (kolor czerwony) nie miała takiego procesu, być może dlatego, że sięgają po nią jedynie bardzo duże korporacje, które stać na to, by przepłacać. MongoDB (kolor żółty) jako bezpłatna alternatywa do Postgresa również otrzymała pewien niewielki zastrzyk zainteresowania.
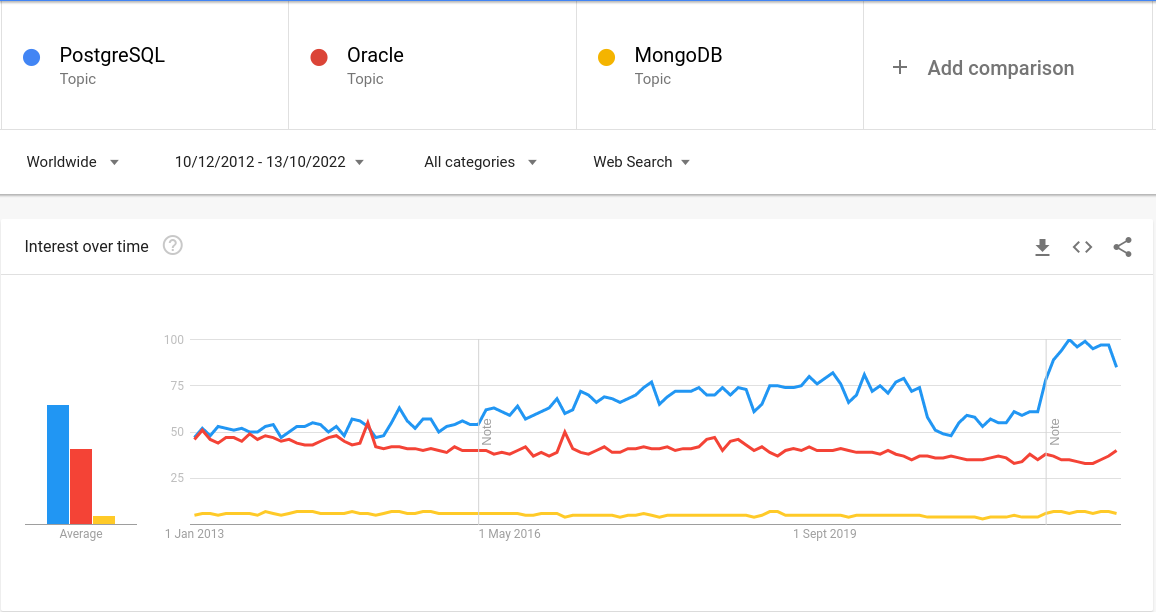
Wykres przedstawia zainteresowanie konkretnymi rozwiązaniami w czasie. Szczyt popularności danej frazy w wyszukiwaniach Google oznaczony został jako wartość 100. Wartość 50 oznacza, że fraza była dwa razy mniej popularna.
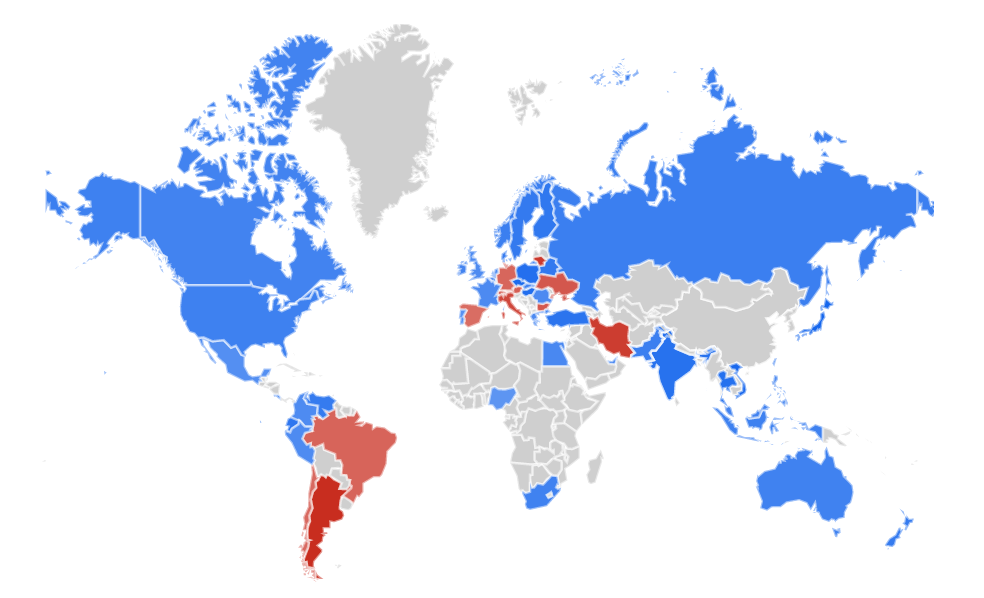
Mapa obrazuje popularność PostgreSQL (niebieski), Oracle DB (czerwony), MongoDB (żółty) na przestrzeni ostatnich 10 lat. Im ciemniejszy jest kolor, tym większą ma przewagę w danym regionie. Kolor szary oznacza brak danych.
PostgreSQL 15 a PostgreSQL 14
Ostatnie wydanie PostgreSQL ustawiło wysoki priorytet na poprawę wydajności. Algorytmy sortowania w pamięci i na dysku zostały unowocześnione, przez co wyniki testów pokazują wzrost wydajności od 25% do nawet 400% w zależności od sortowanych typów danych. Poprawa wydajności w najnowszej wersji PostgreSQL 15 nie zatrzymuje się na tym i obejmuje również funkcje archiwizacji, a także tworzenia kopii zapasowych. Najnowszy PostgreSQL cechuje się też większą elastycznością w zarządzaniu replikacjami logicznymi. Filtrowanie wierszy, listowanie kolumn czy funkcje upraszczające zarządzanie konfliktami to zaledwie kilka z wielu przydatnych funkcji, które oferuje PostgreSQL 15.
Znaczącą różnicę w stosunku do poprzedniej wersji można zauważyć także w nowym formacie logów. Te mogą być teraz przetwarzane w systemach logowania strukturalnego. Konfiguracja samego Postgresa również została poprawiona. Od tej wersji administratorzy mają możliwość nadania użytkownikom uprawnień do zmiany parametrów konfiguracyjnych na poziomie serwera. Dodatkowo użytkownicy mogą teraz wyszukiwać informacje o konfiguracji za pomocą polecenia `\config` z narzędzia wiersza poleceń psql.
Innymi wartymi odnotowania nowościami są zmiany w sposobie gromadzenia statystyk, możliwość ustawienia collate ICU jako domyślnej, dodanie rozszerzenia pg_walinspect, zmiana polityki uprawnień dla schematu publicznego (domyślnego), jak również usunięcie trybu wyłączenia kopii zapasowej i zrezygnowanie ze wsparcia dla Pythona 2 z PL/Python.
Wspomniane informacje to jedynie zauważalne na pierwszy rzut oka zmiany. Aby dowiedzieć się, czego jeszcze można oczekiwać od najświeższego wydania najlepszej bazy danych Open Source, zapraszamy do zapoznania się ze szczegółową listą zmian, dostępną poniżej.
Szczegółowa lista zmian w PostgreSQL 15
Serwer
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Rejestrowanie i sprawdzanie wersji collate dla każdej bazy danych |
Ta funkcja przeznaczona jest do wykrywania zmian wersji collate w celu uniknięcia uszkodzenia indeksu. Funkcja pg_database_collation_actual_version() podaje wersję collate bazowego systemu operacyjnego, a ALTER DATABASE … REFRESH ustawia zarejestrowaną wersję bazy danych tak, aby odpowiadała wersji systemu operacyjnego |
Peter Eisentraut |
| Umożliwiono ustawianie collate ICU jako domyślnej dla klastrów i baz danych |
Poprzednio tylko collate oparte na libc mogło być wybierane na poziomie klastra i bazy danych. Collate ICU można było używać wyłącznie poprzez jawną klauzulę COLLATE |
Peter Eisentraut |
| Dodano widok systemowy pg_ident_file_mappings do raportowania informacji pg_ident.conf |
– |
Julien Rouhaud |
Serwer – partycjonowanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Poprawiono czas planowania dla zapytań odwołujących się do tabel partycjonowanych |
Ta zmiana pomaga, gdy istotnych jest tylko kilka partycji z wielu |
David Rowley |
| Zezwolono na uporządkowane skanowanie partycji |
Poprzednio tabela partycjonowana z partycją DEFAULT lub partycją LIST zawierającą wiele wartości nie mogła być użyta do uporządkowanego skanowania partycji. Teraz może być użyta, jeżeli takie partycje są przycinane (partition pruning) podczas planowania |
David Rowley |
| Poprawiono zachowanie klucza obcego podczas aktualizacji tabel partycjonowanych, przenoszących wiersze między partycjami |
Poprzednio takie aktualizacje uruchamiały akcję usuwania na partycji źródłowej i akcję wstawiania na partycji docelowej. Teraz PostgreSQL uruchomi akcję update na partycji głównej, zapewniając czystszą semantykę |
Amit Langote |
| Zezwolono na użycie CLUSTER w tabelach partycjonowanych |
– |
Justin Pryzby |
| Naprawiono ALTER TRIGGER RENAME w tabelach partycjonowanych, aby poprawnie zmieniał nazwę triggera na wszystkich partycjach |
Klonowane triggery nie mogą teraz zmieniać nazwy |
Arne Roland, Álvaro Herrera |
Serwer – indeksy
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono indeksom btree w tabelach systemowych i TOAST na przechowywanie duplikatów |
Poprzednio de-duplikacja była wyłączona dla tych typów indeksów |
Peter Geoghegan |
| Poprawiono wydajność wyszukiwania indeksów GiST, które zostały zbudowane przy użyciu sortowania |
– |
Aliaksandr Kalenik, Sergei Shoulbakov, Andrey Borodin |
| Umożliwiono ograniczeniom UNIQUE i INDEX traktowanie wartości NULL jako nie różniących się |
Poprzednio wpisy NULL były zawsze traktowane jako wartości różniące się, ale teraz można to zmienić poprzez tworzenie ograniczeń i indeksów z użyciem UNIQUE NULLS NOT DISTINCT |
Peter Eisentraut |
| Umożliwiono operatorowi ^@ starts-with i funkcji starts_with() używanie indeksów btree, jeśli używamy collate C |
Poprzednio mogły one używać tylko indeksów SP-GiST |
Tom Lane |
Server – optimizer
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono rozszerzonym statystykom rejestrowanie statystyk dla rodzica ze wszystkimi jego dziećmi |
Regularne statystyki śledzą osobno statystyki rodzica i rodzica ze wszystkimi potomkami |
Tomas Vondra, Justin Pryzby |
| Dodano zmienną serwera recursive_worktable_factor, aby umożliwić użytkownikowi określenie oczekiwanego rozmiaru tabeli roboczej zapytania rekurencyjnego |
– |
Simon Riggs |
Server – general performance
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono na hash lookup dla klauzul NOT IN z wieloma stałymi |
Poprzednio kod zawsze sekwencyjnie skanował listę wartości |
David Rowley, James Coleman |
| Zezwolono na równoległe wykonywanie SELECT DISTINCT |
– |
David Rowley |
| Przyspieszono walidację kodowania tekstu UTF-8 poprzez przetwarzanie 16 bajtów na raz |
Usprawnia to operacje wymagające dużej ilości tekstu, takie jak COPY FROM |
John Naylor, Heikki Linnakangas |
| Poprawiono wydajność sortowania, które przekracza work_mem |
Gdy dane sortowania nie mieszczą się już w work_mem, należy przełączyć się na algorytm sortowania wsadowego, który wykorzystuje więcej strumieni wyjściowych niż wcześniej |
Heikki Linnakangas |
| Poprawiono wydajność i zmniejszenie zużycia pamięci przez sortowanie w pamięci |
– |
Ronan Dunklau, David Rowley, Thomas Munro, John Naylor |
| Zezwolono na zapisywanie pełnych stron WAL z użyciem kompresji LZ4 i Zstandard |
Jest to kontrolowane przez ustawienie serwera wal_compression |
Andrey Borodin, Justin Pryzby |
| Dodano wsparcie dla zapisu WAL przy użyciu bezpośredniego I/O na macOS |
Działa to tylko jeżeli max_wal_senders = 0 i wal_level = minimal |
Thomas Munro |
| Zezwolono vacuum na śmielsze ustawianie oldest frozen i multi transaction id |
– |
Peter Geoghegan |
| Zezwolono zapytaniu odwołującemu się do wielu tabel obcych na wykonywanie równoległych skanów tabel obcych w większej liczbie przypadków |
– |
Andrey Lepikhov, Etsuro Fujita |
| Poprawiono wydajność funkcji okienkowych wykorzystujących row_number(), rank() dense_rank() i count() |
– |
David Rowley |
| Poprawiono wydajność spinlocków na systemach ARM64 działających na maszynach z dużą liczbą rdzeni |
– |
Geoffrey Blake |
Serwer – monitoring
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Domyślne logowanie punktów kontrolnych i powolnych operacji autovacuum |
Funkcja ta włącza log_checkpoints, a log_autovacuum_min_duration zmienia na 10 minut. Powoduje to, że nawet bezczynny serwer będzie generował logi, co może powodować problemy na serwerach o ograniczonych zasobach bez konfiguracji rotacji logów. W takich przypadkach należy zmienić wartości domyślne |
Bharath Rupireddy |
| Generowanie komunikatów o postępie w dzienniku serwera podczas powolnych startów serwera |
Komunikaty informują o przyczynie opóźnienia. Interwał czasowy dla powiadomienia jest kontrolowany przez nową zmienną serwera log_startup_progress_interval |
Nitin Jadhav, Robert Haas |
| Zapisywanie skumulowanych danych systemowych dotyczących statystyk w pamięci współdzielonej |
Poprzednio dane te były wysyłane do procesu kolektora statystyk za pośrednictwem pakietów UDP i mogły być odczytywane przez sesje tylko po przesłaniu ich przez system plików. Aktualnie nie ma już osobnego procesu dla kolektora statystyk |
Kyotaro Horiguchi, Andres Freund, Melanie Plageman |
| Dodano dodatkowe informacje do komunikatów logowania VACUUM VERBOSE i autovacuum |
– |
Peter Geoghegan |
| Dodano wyjście EXPLAIN (BUFFERS) dla tymczasowych bloków plików I/O |
– |
Masahiko Sawada |
| Zezwolono na tworzenie logów w formacie JSON |
Nowe ustawienie to log_destination = jsonlog |
Sehrope Sarkuni, Michael Paquier |
| Zezwolono pg_stat_reset_single_table_counters() na resetowanie liczników relacji współdzielonych we wszystkich bazach |
– |
Sadhuprasad Patro |
| Dodano wait events dla lokalnych poleceń powłoki |
Nowe wait events są używane podczas wywoływania archive_command, archive_cleanup_command, restore_command i recovery_end_command |
Fujii Masao |
Serwer – uprawnienia
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dostęp do tabel z widoku może być teraz kontrolowany za pomocą uprawnień wywołującego widok |
Poprzednio dostępy do widoków były zawsze traktowane jako wykonywane przez właściciela widoku. Nadal jest to domyślne |
Christoph Heiss |
| Umożliwiono członkom predefiniowanej roli pg_write_server_files wykonywanie kopii zapasowych bazy po stronie serwera |
Poprzednio tylko superużytkownicy mogli wykonywać takie kopie zapasowe |
Dagfinn Ilmari Mannsåker |
| GRANT może przyznawać uprawnienia do zmiany poszczególnych zmiennych serwera poprzez SET i ALTER SYSTEM |
Nowa funkcja has_parameter_privilege() informuje o tym przywileju |
Mark Dilger |
| Dodano predefiniowaną rolę pg_checkpoint, która pozwala członkom uruchamiać CHECKPOINT |
Poprzednio punkty kontrolne mogły być uruchamiane tylko przez superużytkowników |
Jeff Davis |
| Zapewniono członkom predefiniowanej roli pg_read_all_stats dostęp do widoków pg_backend_memory_contexts i pg_shmem_allocations |
Poprzednio dostęp do tych widoków mieli tylko superużytkownicy |
Bharath Rupireddy |
| GRANT może nadawać uprawnienia na pg_log_backend_memory_contexts() |
Poprzednio ta funkcja mogła być uruchamiana tylko przez superużytkowników |
Jeff Davis |
Serwer – konfiguracja serwera
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano zmienną serwera shared_memory_size, aby raportować rozmiar przydzielonej pamięci współdzielonej |
– |
Nathan Bossart |
| Dodano zmienną serwera shared_memory_size_in_huge_pages, aby zgłaszać liczbę wymaganych stron huge memory |
Jest to obsługiwane tylko w systemie Linux |
Nathan Bossart |
| Dodano zmienną serwera shared_preload_libraries w trybie pojedynczego użytkownika |
Ta zmiana wspiera użycie shared_preload_libraries do załadowania niestandardowych metod dostępu i menedżerów zasobów WAL, które byłyby niezbędne dla dostępu do bazy danych nawet w trybie pojedynczego użytkownika |
Jeff Davis |
| Ustawiono, by na systemach typu Solaris domyślnym ustawieniem dynamic_shared_memory_type był sysv |
Poprzedni domyślny wybór, posix, mógł powodować fałszywe błędy na tej platformie |
Thomas Munro |
| Umożliwiono postgres -C prawidłowe raportowanie wartości wyliczanych podczas działania serwera |
Poprzednio podczas działania serwera data_checksums, wal_segment_size i data_directory_mode raportowały wartości, które nie były dokładne na działającym serwerze. |
Nathan Bossart |
Replikacja strumieniowa i przywracanie
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano obsługę kompresji LZ4 i Zstandard dla kopii zapasowych bazy po stronie serwera |
– |
Jeevan Ladhe, Robert Haas |
| Uruchamianie procesów checkpointer i bgwriter podczas odzyskiwania po awarii |
Pomaga to przyspieszyć długie odzyskiwanie po awarii |
Thomas Munro |
| Umożliwiono przetwarzanie WAL w celu wstępnego pobierania potrzebnej zawartości plików |
Jest to kontrolowane przez zmienną serwera recovery_prefetch |
Thomas Munro |
| Umożliwiono archiwizację poprzez ładowalne moduły |
Poprzednio archiwizacja była wykonywana tylko poprzez wywoływanie poleceń powłoki. Nowa zmienna serwera archive_library może być ustawiona w celu określenia biblioteki, która ma być wywołana do archiwizacji |
Nathan Bossart |
| Uruchamianie IDENTIFY_SYSTEM nie jest już wymagane przed START_REPLICATION |
– |
Jeff Davis |
Replikacja strumieniowa i przywracanie – replikacja logiczna
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono na publikację wszystkich tabel w schemacie |
Obsługiwana jest obecnie taka składnia: CREATE PUBLICATION pub1 FOR TABLES IN SCHEMA s1,s2. ALTER PUBLICATION obsługuje podobną składnię. Tabele dodane później do wymienionych schematów również zostaną zreplikowane |
Vignesh C, Hou Zhijie, Amit Kapila |
| Umożliwiono filtrowanie zawartości publikacji za pomocą klauzuli WHERE |
Wiersze niespełniające klauzuli WHERE nie są publikowane |
Hou Zhijie, Euler Taveira, Peter Smith, Ajin Cherian, Tomas Vondra, Amit Kapila |
| Zezwolono na ograniczenie zawartości publikacji do określonych kolumn |
– |
Tomas Vondra, Álvaro Herrera, Rahila Syed |
| Zezwolono na pomijanie transakcji na subskrybencie przy użyciu ALTER SUBSCRIPTION … SKIP |
– |
Masahiko Sawada |
| Dodano wsparcie dla przygotowanych (dwufazowych) transakcji do replikacji logicznej |
W komendzie CREATE_REPLICATION_SLOT dodana została nowa opcja o nazwie TWO_PHASE. pg_recvlogical. Obsługuje ona nowy argument –two-phase |
Peter Smith, Ajin Cherian, Amit Kapila, Nikhil Sontakke, Stas Kelvich |
| Zapobiegnięto logicznej replikacji pustych transakcji |
Poprzednio wydawcy komunikatów wysyłali puste transakcje do subskrybentów, jeżeli subskrybowane tabele nie były modyfikowane |
Ajin Cherian, Hou Zhijie, Euler Taveira |
| Dodanie funkcji SQL do monitorowania zawartości katalogów w slotach replikacji logicznej |
Nowe funkcje to pg_ls_logicalsnapdir(), pg_ls_logicalmapdir(), oraz pg_ls_replslotdir(). Mogą one być uruchamiane przez członków predefiniowanej roli pg_monitor |
Bharath Rupireddy |
| Umożliwiono subskrybentom zatrzymanie wdrażania zmian replikacji logicznej w przypadku wystąpienia błędu |
Funkcja jest włączona przy pomocy opcji subskrybenta disable_on_error i pozwala uniknąć możliwych nieskończonych pętli błędów |
Osumi Takamichi, Mark Dilger |
| Dostosowano zmienne serwera subskrybenta do wydawcy komunikatów, aby wartości datetime i float8 były interpretowane spójnie |
– |
Japin Li |
| Dodano widok systemowy pg_stat_subscription_stats do raportowania aktywności subskrybentów |
Nowa funkcja pg_stat_reset_subscription_stats() pozwala na zresetowanie liczników statystyk |
Masahiko Sawada |
| Zapobiegnięto duplikowaniu wpisów w widoku systemowym pg_publication_tables |
W niektórych przypadkach partycja mogła pojawić się więcej niż raz |
Hou Zhijie |
Komendy użytkowe
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano polecenie SQL MERGE, aby dopasować jedną tabelę do innej |
Działa podobnie jak INSERT … ON CONFLICT, ale jest bardziej zorientowane na batche. |
Simon Riggs, Pavan Deolasee, Álvaro Herrera, Amit Langote |
| Dodano wsparcie dla opcji HEADER w formacie tekstowym COPY |
Nowa opcja powoduje, że nazwy kolumn są wyprowadzane i opcjonalnie weryfikowane na wejściu |
Rémi Lapeyre |
| Dodano nową metodę WAL-logged do tworzenia bazy danych |
Jest to nowa domyślna metoda kopiowania szablonowej bazy danych, ponieważ pozwala uniknąć konieczności stosowania punktów kontrolnych podczas tworzenia bazy danych. Jednak może być powolna, jeżeli baza danych jest duża. Stara metoda nadal jest dostępna |
Dilip Kumar |
| Umożliwiono CREATE DATABASE ustawienie OID bazy danych |
– |
Shruthi Gowda, Antonin Houska |
| Naprawiono błędy DROP DATABASE, DROP TABLESPACE i ALTER DATABASE SET TABLESPACE podczas równoległego użycia w systemie Windows |
– |
Thomas Munro |
| Umożliwiono działanie klucza obcego ON DELETE SET wyłącznie na określone kolumny |
– |
Paul Martinez |
| Umożliwiono ALTER TABLE modyfikację tabeli ACCESS METHOD |
– |
Justin Pryzby, Jeff Davis |
| Poprawiono wywoływanie access hooks do obiektów podczas przepisania tabeli przez ALTER TABLE |
– |
Michael Paquier |
| Umożliwiono tworzenie nielogowanych sekwencji |
– |
Peter Eisentraut |
| Poprawiono śledzenie zależności kolumn w wynikach funkcji zawierających typy złożone, czyli tablice, rekordy i typy wyliczeniowe |
Poprzednio, jeżeli widok lub reguła zawierała odwołanie do konkretnej kolumny, nie było to odnotowywane jako zależność. Widok lub reguła były uważane za zależne tylko od typu złożonego jako całości. Oznaczało to, że upuszczenie pojedynczej kolumny mogło prowadzić do problemów przy użyciu widoku lub reguły |
Tom Lane |
Typy danych
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono, aby precyzja podczas rzutowania na liczbę była ujemna |
Pozwala to na zaokrąglanie wartości na lewo po przecinku, np. ‘1234’::numeric(4, -2) zwraca 1200 |
Dean Rasheed, Tom Lane |
| Poprawiono wykrywanie błędów przepełnienia podczas rzutowania wartości na interwał |
– |
Joe Koshakow |
| Zmieniono format I/O znaków innych niż ASCII “char” |
– |
Tom Lane |
| Uaktualniono informacje o szerokości wyświetlania nowoczesnych znaków Unicode, takich jak emojis |
Zaktualizowano także Unicode 5.0 do 14.0.0. Istnieje teraz zautomatyzowany sposób aktualizacji Unicode w Postgresie |
Jacob Champion |
Funkcje
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano wielozakresowe wejście dla range_agg() |
– |
Paul Jungwirth |
| Dodano agregaty MIN() i MAX() dla typu danych xid8 |
– |
Ken Kato |
| Dodano funkcje wyrażeń regularnych dla kompatybilności z innymi systemami relacyjnymi |
Nowe funkcje to regexp_count(), regexp_instr(), regexp_like() oraz regexp_substr(). Dodano również kilka nowych opcjonalnych argumentów do regexp_replace() |
Gilles Darold, Tom Lane |
| Dodano możliwość obliczania odległości między wielokątami |
– |
Tom Lane |
| Dodano do_char() kody formatu of, tzh i tzm |
Odpowiedniki tych kodów pisane wielkimi literami były już obsługiwane |
Nitin Jadhav |
| Przy stosowaniu AT TIME ZONE używany jest czas rozpoczęcia transakcji, aby określić, czy DST ma zastosowanie |
Pozwala to, aby konwersja była uważana za stabilną, a dodatkowo minimalizuje zapytania do jądra |
Aleksander Alekseev, Tom Lane |
| Ignorowanie NULL podczas wykonywania funkcji ts_delete() i setweight() |
Funkcje te efektywnie ignorują elementy tablicowe typu empty-string (ponieważ te nigdy nie mogłyby pasować do poprawnego leksemu). Wydaje się spójne, aby pozwolić im również ignorować elementy NULL, zamiast wyrzucać błąd |
Jean-Christophe Arnu |
| Dodano wsparcie dla jednostek petabajtowych do pg_size_pretty() i pg_size_bytes() |
– |
David Christensen |
| Zmieniono pg_event_trigger_ddl_commands(), aby wyprowadzać referencje do tymczasowych schematów innych sesji używając aktualnej nazwy schematu |
Poprzednio funkcja ta nazywała wszystkie zwrócone, tymczasowe schematy jako pg_temp i było to mylące |
Tom Lane |
PL/pgSQL
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Poprawka egzekwowania oznaczeń zmiennych CONSTANT w PL/pgSQL |
Poprzednio zmienna mogła być użyta jako parametr wyjściowy CALL lub zmienna OPEN refcursora pomimo oznaczenia CONSTANT |
Tom Lane |
libpq
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono na dopasowanie adresu IP do Subject Alternative Name branego z certyfikatu serwera |
– |
Jacob Champion |
| Zezwolono PQsslAttribute() na raportowanie typu biblioteki SSL bez konieczności połączenia libpq |
– |
Jacob Champion |
| Zmieniono anulowanie zapytań wysyłanych przez klienta tak, aby używały tych samych ustawień TCP co normalne połączenia |
Pozwala to skonfigurowanym timeoutom TCP stosować się do połączeń query cancel |
Jelte Fennema |
Zabroniono zgłaszanie błędów libpq event callback podczas umyślnego zwrócenia błędu
|
– |
Tom Lane |
Client Applications
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Pozwolono, aby pgbench ponownie spróbował się wykonać po błędach serializacji i deadlock’u |
– |
Yugo Nagata, Marina Polyakova |
Aplikacje klienckie – psql
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Poprawiono wydajność polecenia psql’s \copy poprzez wysyłanie danych w większych porcjach |
– |
Heikki Linnakangas |
| Dodano polecenie \config do raportowania zmiennych serwera |
Działa to podobnie do polecenia SHOW, ale może przetwarzać wzorce, aby wygodnie pokazać wiele zmiennych |
Mark Dilger, Tom Lane |
| Dodano polecenie \getenv służące przypisaniu wartości zmiennej środowiskowej do zmiennej psql |
– |
Tom Lane |
| Dodano opcję + do poleceń \lo_list i \dl w celu pokazania uprawnień obiektów typu large-object |
– |
Paweł Luzanow |
| Dodano opcję pagera dla polecenia \watch |
Jest to obsługiwane tylko w systemie Unix i jest kontrolowane przez zmienną środowiskową PSQL_WATCH_PAGER |
Pavel Stehule, Thomas Munro |
| Psql uwzględnia wewnątrzpytaniowe komentarze z podwójnym myślnikiem w zapytaniach wysyłanych do serwera |
Poprzednio takie komentarze były usuwane z zapytania przed wysłaniem. Komentarze z podwójnym myślnikiem, które znajdują się przed jakimkolwiek tekstem zapytania, nie są wysyłane i nie są rejestrowane jako osobne wpisy w historii psql |
Tom Lane, Greg Nancarrow |
| Poprawiono psql tak, aby polecenie meta-# Readline wstawiało znacznik komentarza z podwójnym myślnikiem |
Poprzednio wstawiany był znacznik funta, chyba że użytkownik zadał sobie trud skonfigurowania niedomyślnego znacznika komentarza |
Tom Lane |
| Umożliwiono psql wyprowadzanie wszystkich wyników, gdy wiele zapytań jest przekazywanych do serwera jednocześnie |
Poprzednio wyświetlany był tylko ostatni wynik zapytania. Stare zachowanie może być przywrócone przez ustawienie zmiennej psql SHOW_ALL_RESULTS na off |
Fabien Coelho |
| W przypadku wykrycia błędu w trybie –single-transaction i włączeniu ON_ERROR_STOP, końcowe polecenie COMMIT zmieniane jest na ROLLBACK |
Poprzednio wykrycie błędu w poleceniu -c lub pliku skryptu -f prowadziło do wydania ROLLBACK na końcu, niezależnie od wartości ON_ERROR_STOP |
Michael Paquier |
| Ulepszenie uzupełniania zakładek w psql |
– |
Shinya Kato, Dagfinn Ilmari Mannsåker, Peter Smith, Koyu Tanigawa, Ken Kato, David Fetter, Haiying Tang, Peter Eisentraut, Álvaro Herrera, Tom Lane, Masahiko Sawada |
| Ograniczono obsługę poleceń backslash w psql dla serwerów z wersją PostgreSQL 9. 2 lub nowszą |
Usunięto kod, który był używany tylko podczas pracy ze starszym serwerem. Polecenia, które uległy wycofaniu były kompatybilne jedynie z wersjami poniżej 9.2 |
Tom Lane |
Aplikacje klienckie – pg_dump
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Sprawiono, aby pg_dump zrzucał również publiczne zmiany własności i etykiety bezpieczeństwa schematu |
– |
Noah Misch |
| Poprawiono wydajność zrzucania baz danych z większą liczbą obiektów |
Poprawi to również wydajność pg_upgrade. |
Tom Lane |
| Poprawiono wydajność równoległego pg_dump dla tabel z dużymi tablicami TOAST |
– |
Tom Lane |
| Dodano opcję dump/restore –no-table-access, aby wymusić przywrócenie tylko domyślnej metody dostępu do tabel |
– |
Justin Pryzby |
| Ograniczono obsługę pg_dump i pg_dumpall do serwerów z PostgreSQL w wersji 9. 2 lub nowszej |
– |
Tom Lane |
Zastosowania serwera
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano nową opcję pg_basebackup –target, aby kontrolować lokalizację bazowej kopii zapasowej |
Nowymi opcjami są server – używana, aby zapisać kopie zapasową lokalnie oraz blackhole – która pozwala wyrzucić kopię zapasową (do testów) |
Robert Haas |
| Zezwolono pg_basebackup na kompresję gzip, LZ4 i Zstandard po stronie serwera oraz kompresję LZ4 i Zstandard po stronie klienta dla plików bazowej kopii zapasowej |
Kompresja gzip po stronie klienta była już obsługiwana |
Dipesh Pandit, Jeevan Ladhe |
| Zezwolono pg_basebackup na kompresję po stronie serwera i dekompresję po stronie klienta przed zapisem |
Jest to możliwe dzięki ustawieniu kompresji po stronie serwera i formatu plain na wyjściu |
Dipesh Pandit |
| Zezwolono opcji –compress pg_basebackup na kontrolę miejsca kompresji (serwer lub klient), metody kompresji i opcji kompresji |
– |
Michael Paquier, Robert Haas |
| Dodano metodę kompresji LZ4 do pg_receivewal |
Działa to przez –compress=lz4 i wymaga zbudowania binariów przy użyciu –with-lz4 |
Georgios Kokolatos |
| Dodano dodatkowe możliwości do opcji –compress pg_receivewal |
– |
Georgios Kokolatos |
| Poprawiono zdolność pg_receivewal do restartu we właściwej lokalizacji WAL |
Poprzednio pg_receivewal uruchamiał się w oparciu o plik WAL z lokalnego katalogu archive lub bieżącej lokalizacji WAL flush serwera wysyłającego. Dzięki tej zmianie, jeżeli lokalny katalog archive jest pusty i znany jest replication slot, punkt restartu replication slot będzie użyty |
Ronan Dunklau |
| Dodano opcję pg_rewind –config-file, aby uprościć użycie, gdy pliki konfiguracyjne serwera są przechowywane poza katalogiem danych |
– |
Gunnar Bluth |
Zastosowanie serwera – pg_upgrade
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Pliki tymczasowe oraz log pg_upgrade będą przechowywane w podkatalogu nowego klastra o nazwie pg_upgrade_output.d |
Poprzednio takie pliki były pozostawiane w bieżącym katalogu, co wymagało ręcznego czyszczenia. Teraz są one automatycznie usuwane po pomyślnym zakończeniu pg_upgrade |
Justin Pryzby |
| Wyłączono domyślne raportowanie statusu podczas operacji pg_upgrade, jeżeli wyjściem nie jest terminal |
Wyjście raportowania statusu może być włączone dla użycia non-tty przez użycie –verbose. |
Andres Freund |
| Sprawiono, że pg_upgrade zgłasza wszystkie bazy danych z niepoprawnymi ustawieniami połączenia |
Poprzednio raportowana była tylko pierwsza baza z nieprawidłowym połączeniem |
Jeevan Ladhe |
| Sprawiono, aby pg_upgrade zachowywał OID dla przestrzeni tabel, baz danych, jak również dla numerów węzłów relacyjnych |
– |
Shruthi Gowda, Antonin Houska |
| Dodano opcję –no-sync do pg_upgrade |
Użycie jest zalecane jedynie do testów |
Michael Paquier |
| Ograniczono wsparcie pg_upgrade do starych serwerów z PostgreSQL w wersji 9. 2 lub starszych |
– |
Tom Lane |
Aplikacje serwerowe – pg_waldump
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano możliwość filtrowania outputu pg_waldump według węzła pliku relacji, numeru bloku, numeru forka i obrazów pełnych stron |
– |
David Christensen, Thomas Munro |
| Zmieniono pg_waldump, aby logował statystyki przed przerwaniem outputu |
Na przykład, użycie Ctrl+C w terminalu z uruchomionym pg_waldump –stats –follow zgłosi bieżące statystyki przed wyjściem. Nie działa to w systemie Windows |
Bharath Rupireddy |
| Poprawiono opisy niektórych rekordów WAL transakcji raportowanych przez pg_waldump |
– |
Masahiko Sawada, Michael Paquier |
| Umożliwiono pg_waldump zrzucanie informacji o menedżerach zasobów |
Służy do tego opcja –rmgr, której można używać wielokrotnie |
Heikki Linnakangas |
Dokumentacja
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano dokumentację dla pg_encoding_to_char() i pg_char_to_encoding() |
– |
Ian Lawrence Barwick |
| Dokumentacja operatora ^@ starts-with |
– |
Tom Lane |
Kod źródłowy
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Dodano wsparcie dla testów continuous integration przy użyciu cirrus-ci |
– |
Andres Freund, Thomas Munro, Melanie Plageman |
| Dodano opcję configure –with-zstd, aby włączyć kompilacje Zstandard |
– |
Jeevan Ladhe, Robert Haas, Michael Paquier |
| Dodano pole id ABI do magic block w ładowanych bibliotekach, umożliwiając dystrybucjom non-community PostgreSQL prawidłową identyfikację bibliotek, niekompatybilnych z innymi buildami |
Niedopasowanie pola ABI wygeneruje błąd podczas ładowania. |
Peter Eisentraut |
| Utworzono nową wartość pg_type.typcategory dla “char” |
Do tej kategorii przypisane zostały również niektóre inne typy do użytku wewnętrznego |
Tom Lane |
| Dodano nową wiadomość protokołu TARGET, aby określić nową metodę COPY, która ma być używana dla kopii zapasowych bazy |
pg_basebackup używa teraz tej metody |
Robert Haas |
| Dodano nową wiadomość protokołu COMPRESSION i COMPRESSION_DETAIL, aby określić metodę kompresji i opcje |
– |
Robert Haas |
| Usunięto wsparcie serwera dla starej składni polecenia BASE_BACKUP i protokołu bazowej kopii zapasowej |
– |
Robert Haas |
| Dodano wsparcie dla rozszerzeń w zakresie ustawiania niestandardowych celów tworzenia kopii zapasowych |
– |
Robert Haas |
| Umożliwiono rozszerzeniom definiowanie niestandardowych menedżerów zasobów WAL |
– |
Jeff Davis |
| Dodano funkcję pg_settings_get_flags(), aby uzyskać flagi zmiennych serwera |
– |
Justin Pryzby |
| W systemie Windows wyeksportowano wszystkie zmienne globalne serwera za pomocą znaczników PGDLLIMPORT |
Poprzednio w Windowsie tylko określone zmienne były dostępne dla rozszerzeń |
Robert Haas |
| Wymaganie GNU make w wersji 3.81 lub nowszej do budowy PostgreSQL |
– |
Tom Lane |
| Wymaganie OpenSSL do budowy rozszerzenia pgcrypto |
– |
Peter Eisentraut |
| Wymaganie Perl w wersji 5. 8.3 lub nowszej |
– |
Dagfinn Ilmari Mannsåker |
| Wymaganie Python w wersji 3. 2 lub nowszej |
– |
Andres Freund |
Dodatkowe moduły
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Umożliwiono amcheck sprawdzanie sekwencji |
– |
Mark Dilger |
| Poprawiono kontrolę poprawności amcheck dla tabel TOAST |
– |
Mark Dilger |
| Dodano nowy moduł basebackup_to_shell jako przykład niestandardowego celu tworzenia kopii zapasowych |
– |
Robert Haas |
| Dodano nowy moduł basic_archive jako przykład wykonywania archiwizacji przez bibliotekę |
– |
Nathan Bossart |
| Zezwolono na indeksy btree_gist na kolumnach boolean |
Mogą one być używane do ograniczeń wykluczenia |
Emre Hasegeli |
| Poprawiono pageinspect page_header() do obsługi 32-kilobajtowych rozmiarów stron |
Poprzednio w niektórych przypadkach mogły być zwracane nieprawidłowe wartości ujemne |
Quan Zongliang |
| Dodano liczniki dla tymczasowych bloków plików I/O do pg_stat_statements |
– |
Masahiko Sawada |
| Dodano liczniki JIT do pg_stat_statements |
– |
Magnus Hagander |
| Dodano nowy moduł pg_walinspect |
Daje on wyjście na poziomie SQL podobne do pg_waldump. |
Bharath Rupireddy |
| Dodano informacje o stanie (permissive/enforcing) w komunikatach logów sepgsql |
– |
Dave Page |
Dodatkowe moduły – postgres_fdw
| Zmiana |
Dodatkowe informacje |
Autor/Autorzy |
| Zezwolono postgres_fdw na upychanie wyrażeń CASE |
– |
Alexander Pyhalov |
| Dodano zmienną serwerową postgres_fdw. application_name do kontroli nazwy aplikacji w połączeniach postgres_fdw |
Poprzednio nazwa aplikacji sesji zdalnej mogła być ustawiona tylko na zdalnym serwerze lub poprzez specyfikację połączenia postgres_fdw. postgres_fdw. application_name obsługuje pewne sekwencje specjalne, ułatwiając odróżnienie takich połączeń na zdalnym serwerze |
Hayato Kuroda |
| Zezwolono na równoległe wykonywanie commitów na serwerach postgres_fdw |
Jest to włączone za pomocą opcji CREATE SERVER parallel_commit |
Etsuro Fujita |
Podsumowanie i słowo o twórcach
Często patrząc na produkt, nie widzimy stojących za nim ludzi. Nie widzimy tych, którzy włożyli swoje serce i poświęcili czas na stworzenie go. Dobrym doświadczeniem dla naszej wyobraźni jest więc, aby od czasu do czasu spojrzeć na produkt od innej strony. Postaramy się w kilku słowach przybliżyć obraz twórców Postgresa. PostgreSQL Global Development Group jest prywatną firmą non-profit, znaną na rynku od 26 lat. Niezmiennie od ponad 15 lat aktywnie zajmuje się poprawą jakości systemu bazodanowego PostgreSQL. Aktualnie zrzesza 71 specjalistów, a przynajmniej taka liczba widnieje na jej oficjalnym profilu w LinkedIn. Firma zaznacza, że jej główne biuro znajduje się w Stanach Zjednoczonych – nie określa jednak gdzie konkretnie. Co ciekawe, zapytane o to Google Maps wskazuje Kanadę. Może jednak w rzeczywistości PostgreSQL Global Development Group nie posiada swojego biura i każdy pracuje z dowolnego miejsca na świecie? Jednego jesteśmy pewni – nie ważne, gdzie wykonują swoją pracę – robią ją znakomicie, a każda nowa wersja staje się standardem pracy dla milionów deweloperów.

 2022-10-31
2022-10-31