
 2018-03-22
2018-03-22
Tips & Tricks – Poradnik psql cz. II. – pisanie prostych skryptów
Kolejna odsłona porad związanych z psql: rozwiniemy temat posługiwania się psql w trybie interaktywnym, pokażemy zastosowania trybu nieinteraktywnego i funkcjonalności z najnowszych wersji narzędzia.
Kolejna odsłona porad związanych z psql: rozwiniemy temat posługiwania się psql w trybie interaktywnym, pokażemy zastosowania trybu nieinteraktywnego i funkcjonalności z najnowszych wersji narzędzia.
Tryb interaktywny
W poprzedniej części wspomnieliśmy o komendzie \e[f/v], za pomocą której możemy edytować bufor lub ciało funkcji czy widoku. Nie ulega wątpliwości, że jest to użyteczne przy drobnej korekcie, jednak dłuższe zapytanie znacznie wygodniej tworzyć w osobnym pliku. Plik taki z łatwością możemy wywołać za pomocą metakomendy \i, podając ścieżkę do niego:
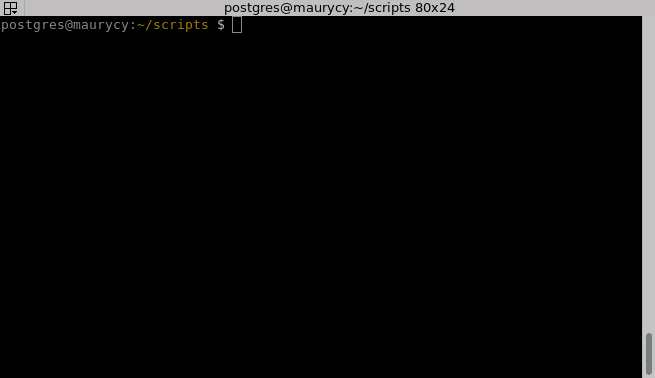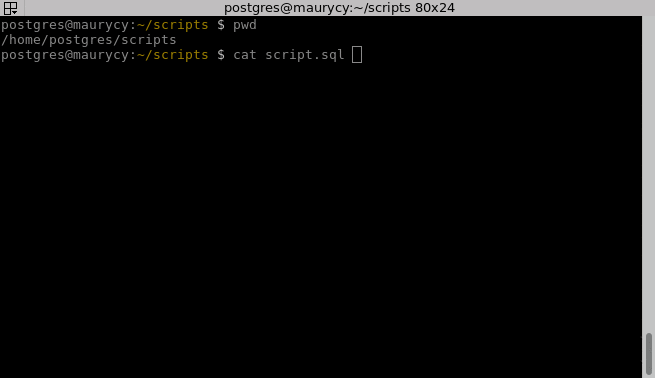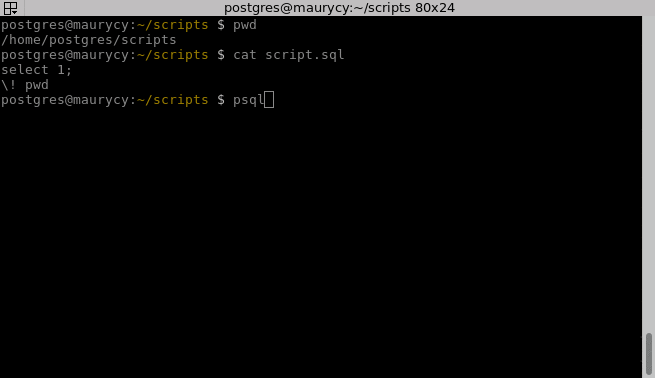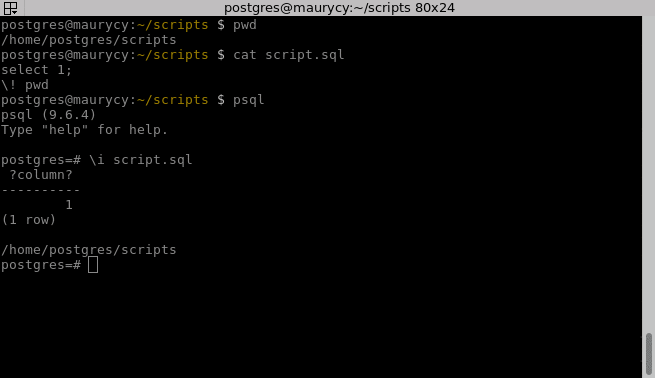
\! wykonuje komendę shellową, zatem \! pwd pokazuje bieżący katalog roboczy. Możemy tu zaobserwować jeszcze jedną użyteczną informację – w naszym pliku połączyliśmy kwerendę SQL i metapolecenie psql.
Stosunkowo mało znaną funkcjonalnością jest możliwość definiowania własnych zmiennych za pomocą polecenia \gset lub omawianego poprzednio \set:
\gset— do zmiennej przekazywany jest wynik zapytania z buforu,\set— wprost definiujemy wartość zmiennej, może być to zapytanie, ale zmienna będzie wówczas przechowywała jego ciało, nie wynik.

Zwróćmy uwagę na kilka rzeczy:
- zmienną
:var1zdefiniowaliśmy jako\set var1 'select count(1) from pg_tables', zatem, aby otrzymać wynik zapytania z tej zmiennej, musimy wywołanie zakończyć średnikiem, - do zdefiniowanych zmiennych możemy się odwoływać, poprzedzając ich nazwę dwukropkiem,
- zmiennych możemy także używać w zapytaniu,
- za pomocą
\gsetmożemy zdefiniować więcej niż jedną zmienną na raz.
Skoro mamy już zmienne to co z instrukcjami warunkowymi? Są (choć dopiero w wersji 10. klienta):

Użytkownicy konsoli Linuksa znają małe, przydatne polecenie watch, które w pętli co zadany interwał wykonuje komendę otrzymaną na wejściu – w ten sposób łatwo obserwować np. przyrost zajęcia powierzchni dyskowej. Znajdziemy je także w psql:

Tryb nieinteraktywny
Czynności cykliczne są często zautomatyzowane i nie wymagają ingerencji użytkownika. Jeśli potrzebujemy wykonać je także na bazie, w sukurs przychodzi nam właśnie psql, które możemy uruchomić z opcjami:
-f— przyjmuje ścieżkę do skryptu (odpowiednik\iw trybie interaktywnym),-c— przyjmuje zapytanie lub komendę psql (np.-c”\dt”).
Obydwie opcje spowodują, że psql uruchomi się, wykona podany skrypt czy komendę i zakończy działanie. Począwszy od wersji 9.6 narzędzia, możemy łączyć wiele parametrów -c i/lub -f:

Cały zestaw instrukcji z parametru jest objęty osobną transakcją, z każdego też dostaniemy output. Output możemy przekierować do pliku za pomocą parametru -o podając ścieżkę do pliku (ten sam efekt osiągniemy w trybie interaktywnym poprzez \o ). Polecenia będą wykonywane w kolejności, w której je przekazujemy. Jeśli dodatkowo użyjemy parametru -1, całość (tj. wszystkie zapytania zawarte w parametrach -c czy -f) zostanie objęta transakcją:

Jak wspominaliśmy w poprzedniej części, psql domyślnie korzysta z plików typu rc (run command lub resource control). Jednak najczęściej nie chcemy, aby w tym trybie nieinteraktywnym te komendy były wykonywane, dlatego warto pamiętać o opcji -X |–no-psqlrc.
Jednym z zastosowań trybu nieinteraktywnego może być tworzenie cyklicznych raportów. Na potrzeby artykułu stworzyliśmy tabelę, której zadaniem będzie przechowywanie informacji o wypożyczeniach książki:
CREATE TABLE tv_book_reader (
borrow_date date NOT NULL,
book_id integer NOT NULL,
reader_id integer NOT NULL
);
ALTER TABLE ONLY tv_book_reader
ADD CONSTRAINT tv_book_reader_pkey
PRIMARY KEY (borrow_date, book_id, reader_id);
(tabelę tę zasililiśmy losowymi danymi stworzonymi za pomocą jednego z modułów EuroDB).
Hipotetycznie naszym zadaniem jest stworzenie raportu o tym, ile książek dany czytelnik wypożyczył w każdym miesiącu 2017 roku.
Samo zapytanie jest raczej banalne, wyniki jednak chcielibyśmy zaprezentować czytelny sposób — na przykład za pomocą tabeli przestawnej (pivot table), gdzie nagłówkiem poziomym byłby kolejne miesiące, a pionowym identyfikatory czytelników.
Wynik naturalnie chcielibyśmy zapisać do pliku, ale tym razem chcielibyśmy zakodować dokument w formacie csv.
Złóżmy zatem nasze założenia w całość:
Skrypt:
postgres@maurycy:~/scripts $ cat -n report.sql
1 SELECT
2 extract(month FROM borrow_date) AS month
3 , reader_id "reader / month"
4 , count(1)
5 FROM
6 tv_book_reader
7 WHERE
8 borrow_date BETWEEN :'start'::date
9 AND :'stop'::date
10 GROUP BY
11 1
12 , 2
13 ORDER BY
14 1
15 , 3 DESC \crosstabview "reader / month" month
- linie 8 i 9: do klauzuli WHERE przekazujemy zmienne, zdefiniowane później w wywołaniu – zwróćmy uwagę na składnię wynikającą z rzutowania typów,
- linia 15: przekształcamy wynik do tabeli przestawnej i definiujemy kolejno nagłówek pionowy i poziomy.
Wywołanie:
postgres@maurycy:~/scripts $ psql -d library \ -f report.sql -o report.csv \ -v start='2017-01-01' -v stop='2017-12-31' \ -A -F ','
-v– odpowiednik\setw trybie interaktywnym, definiujemy zmienne nazwa=wartość-A– odpowiednik\pset format unalignedsprawia, że wszystkie kolumny wynikowe wypisywane są w jednej linii, rozdzielane tym, co zdefiniujemy jako zmiennąfieldsep, innymi słowy separatorem kolumn,-F– odpowiednik\pset fieldsep ','– separator kolumn,- nie definiujemy separatora rekordów, domyślnie jest to znak nowej linii.
Efekt:
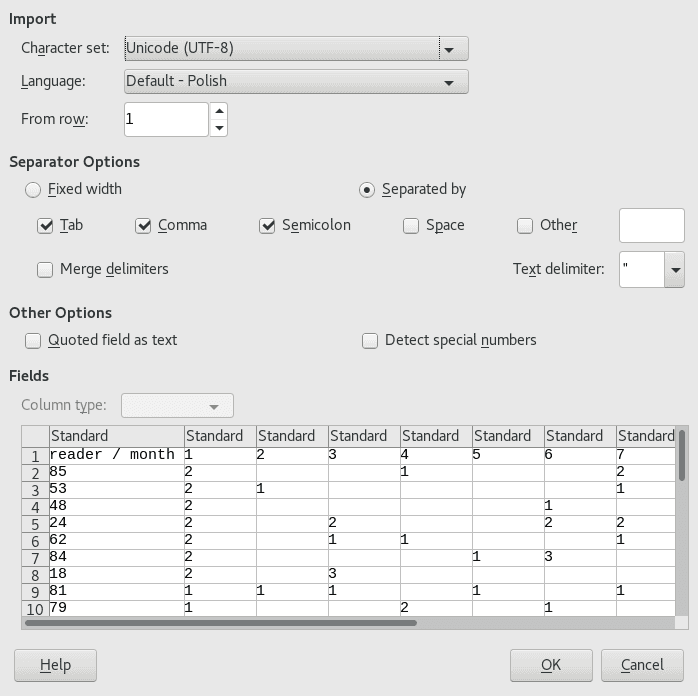
Przy takiej budowie możemy w łatwy sposób nie tylko modyfikować zakres czasowy raportu (zmiana wartości zmiennych), ale też zmieniać format pliku wynikowego, na przykład na html (wskazówka: -A i -F zastąpić -H i przyjrzeć się opcjom \pset, głównie tableattr).
Podsumowanie
W kolejnej części naszego cyklu artykułów postaramy się przybliżyć Państwu ciekawe triki związane z plikiem .psqlrc. Mamy nadzieję przekonać Czytelników do korzystania z tego zgrabnego i funkcjonalnego narzędzia, jakim jest psql.
psql – Tips & Tricks
psql – Tips & Tricks II – ten materiał
psql – Tips & Tricks III
Źródła:
https://www.postgresql.org/docs/9.6/static/app-psql.html
https://www.postgresql.org/docs/10/static/app-psql.html